TorchInductor GPU 效能分析#
創建於: 2023年7月28日 | 最後更新於: 2025年6月10日
本節列出了有助於深入瞭解 TorchInductor 中模型效能的有用命令和工作流。當模型執行速度不如預期時,您可能需要檢查模型的各個核心。通常,佔用大部分 GPU 時間的核心是最值得關注的。之後,您可能還想直接執行各個核心並檢查其效能。PyTorch 提供了涵蓋上述所有內容的工具。
相關的環境變數#
您可以在分析中使用以下環境變數
TORCHINDUCTOR_UNIQUE_KERNEL_NAMES預設情況下,TorchInductor 將 Triton 核心命名為
‘triton\_’。當啟用此環境變數時,Inductor 會在跟蹤中生成更有意義的核心名稱,例如triton_poi_fused_cat_155,其中包含核心類別(poi代表逐點操作)和原始 ATen 運算子。此配置預設停用,以提高編譯快取命中率。
TORCHINDUCTOR_BENCHMARK_KERNEL啟用此選項將使 Inductor 程式碼生成器能夠對各個 Triton 核心進行基準測試。
TORCHINDUCTOR_MAX_AUTOTUNEInductor 自動調優器將對更多
triton.Configs進行基準測試,並選擇效能最佳的配置。這將增加編譯時間,但有望提高效能。
分解模型 GPU 時間#
以下是將模型執行時間分解到各個核心的步驟。我們以 mixnet_l 為例。
為模型執行基準測試指令碼
TORCHINDUCTOR_UNIQUE_KERNEL_NAMES=1 TORCHINDUCTOR_BENCHMARK_KERNEL=1 python -u benchmarks/dynamo/timm_models.py –backend inductor –amp –performance –dashboard –only mixnet_l –disable-cudagraphs –training
注意
該工具依賴於核心名稱來決定其類別。啟用
TORCHINDUCTOR_UNIQUE_KERNEL_NAMES對此至關重要。在輸出日誌中,查詢以下行
**Compiled module path: /tmp/torchinductor_shunting/qz/cqz7hvhood7y3psp7fy6msjxsxyli7qiwiybizdwtjw6ffyq5wwd.py**
我們為每個編譯的模組有一行。如果沒有額外的圖中斷,我們將在日誌中看到 2 行這樣的內容,一行用於前向圖,一行用於後向圖。
對於我們的示例命令,我們分別獲得前向圖和後向圖的編譯模組如下
現在我們可以深入瞭解每個獨立編譯模組的效能。為了說明方便,我們選擇前向圖的模組。我將其命名為
fwd.py。使用-p引數直接執行它**> python fwd.py -p**
在此 示例 gist 中檢視完整的輸出日誌
在輸出中,您會注意到以下內容
我們為效能分析寫入了一個 chrome trace 檔案,因此我們可以載入該跟蹤並與之互動。在日誌中,查詢如下的行以找到 trace 檔案的路徑。
效能分析的 Chrome trace 已寫入 /tmp/compiled_module_profile.json
將跟蹤載入到 Chrome 中(訪問 chrome 瀏覽器中的 chrome://tracing 並按照 UI 的提示載入檔案)將顯示如下 UI
您可以放大和縮小來檢查效能分析。
我們透過類似以下的日誌行報告 GPU 忙碌時間佔總時間的百分比
GPU 忙碌時間百分比:102.88%
有時您可能會看到大於 100% 的值。原因在於 PyTorch 在啟用效能分析時使用核心執行時間,而在停用效能分析時使用總時間。效能分析可能會稍微扭曲核心執行時間。但總體來說應該不是大問題。
如果我們像這樣執行
densenet121模型,並使用較小的批次大小,我們會看到 GPU 忙碌時間百分比較低(Forward graph) Percent of time when GPU is busy: 32.69%
這表明模型存在大量 CPU 開銷。這與啟用 cudagraphs 大大提高了 densenet121 的效能這一事實一致。
我們可以將 GPU 時間分解到不同類別的核心。在
mixnet_l示例中,我們看到逐點核心佔 28.58%
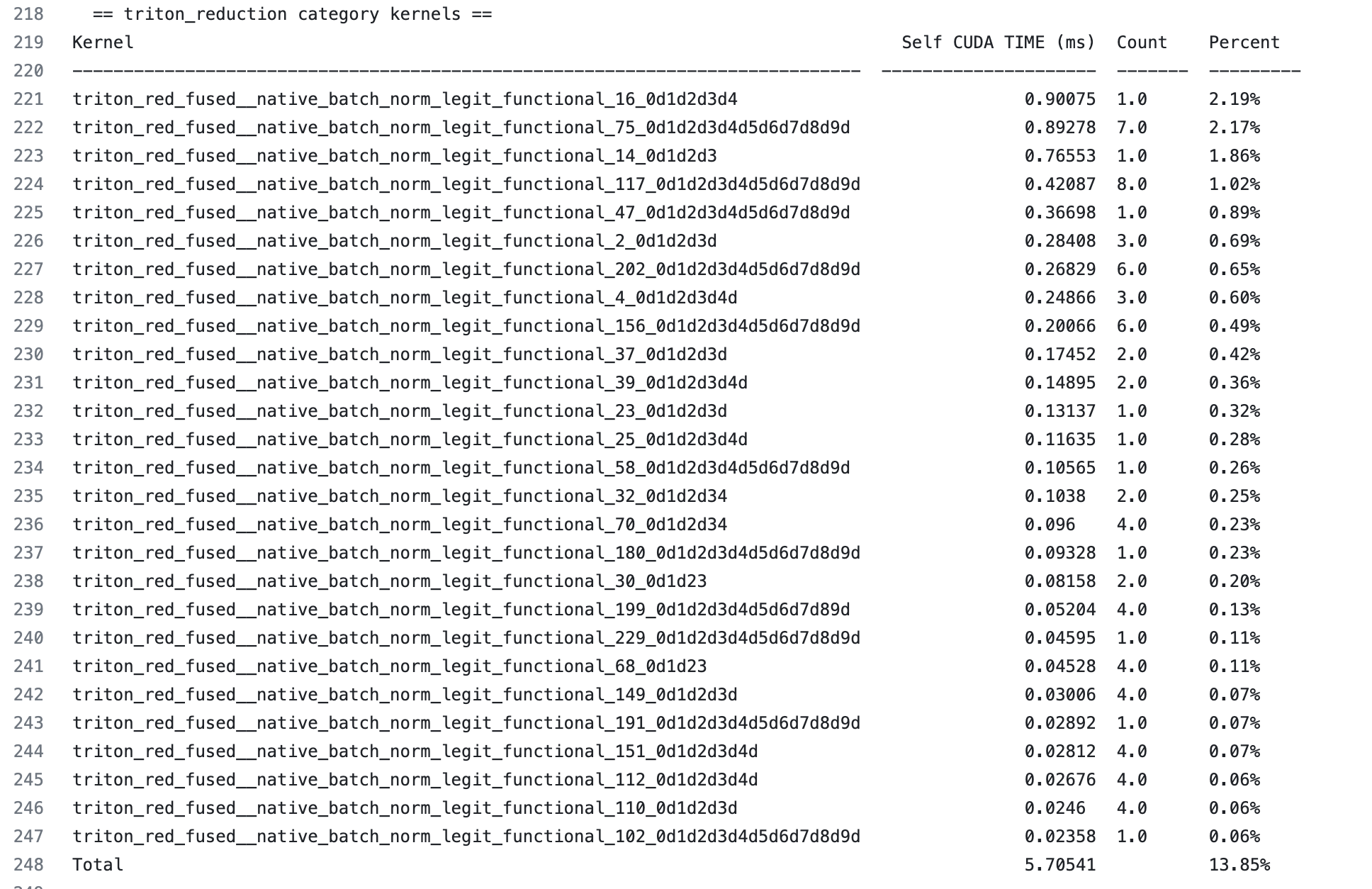
歸約核心佔 13.85%
持久化歸約核心佔 3.89%
其餘為用於 mm/conv 的 cutlass/cudnn 核心,佔 56.57%
此資訊可以在每個核心類別的報告的摘要行(最後一行)中找到。
我們還可以深入到某一類核心。例如,讓我們檢查歸約核心
我們可以看到每個獨立歸約核心執行時間的排序表。我們還可以看到核心執行的次數。這在幾個方面很有幫助
如果一個核心只佔用很小的時間,例如 0.1%,改進它最多隻能帶來 0.1% 的總體收益。不值得花費大量精力。
如果一個核心佔 2% 的時間,將其改進 2 倍可以帶來 1% 的總體收益,這證明了付出的努力是值得的。
基準測試單個 Triton 核心#
假設我們想仔細檢視 triton_red_fused\__native_batch_norm_legit_functional_16,它是最昂貴的歸約核心,在前向圖的總體執行時間中佔 2.19%。
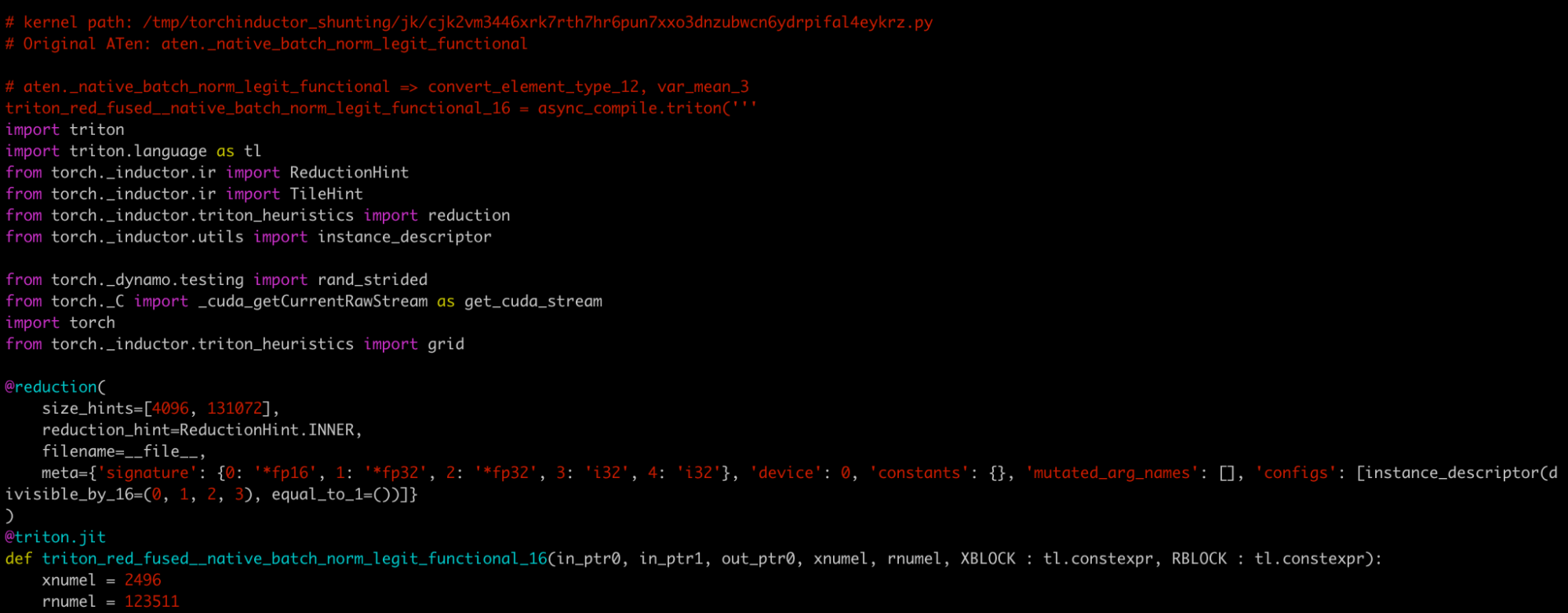
我們可以在 fwd.py 中查詢核心名稱,並找到類似這樣的註釋
# kernel path: /tmp/torchinductor_shunting/jk/cjk2vm3446xrk7rth7hr6pun7xxo3dnzubwcn6ydrpifal4eykrz.py

為了方便起見,我將其重新命名為 k.py。這是此 檔案 的貼上內容。
k.py 是一個獨立的 Python 模組,包含核心程式碼及其基準測試。
直接執行 k.py 將報告其執行時間和頻寬

我們可以透過執行以下命令來檢查 max-autotune 是否對此核心有幫助
**TORCHINDUCTOR_MAX_AUTOTUNE=1 python /tmp/k.py**
我們還可以暫時新增更多歸約啟發式規則並重新執行指令碼,以檢查這些規則如何幫助核心。
