CyclicLR#
- class torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr, max_lr, step_size_up=2000, step_size_down=None, mode='triangular', gamma=1.0, scale_fn=None, scale_mode='cycle', cycle_momentum=True, base_momentum=0.8, max_momentum=0.9, last_epoch=-1)[source]#
根據迴圈學習率策略(CLR)設定每個引數組的學習率。
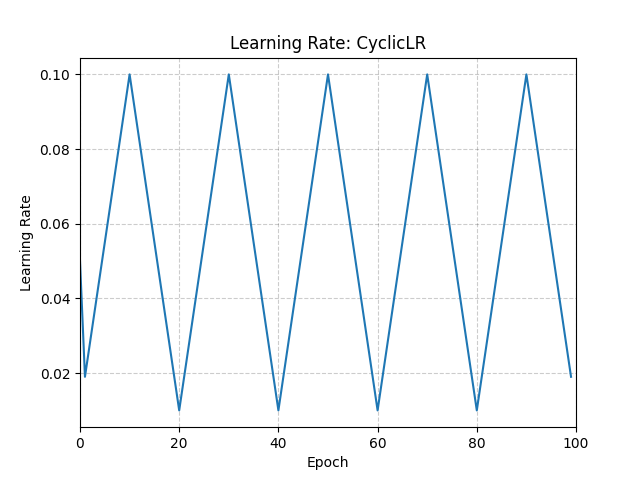
該策略在恆定頻率下在兩個邊界之間迴圈學習率,如論文 Cyclical Learning Rates for Training Neural Networks 中詳述。兩個邊界之間的距離可以按每次迭代或每個週期進行縮放。
迴圈學習率策略會在每個 batch 之後更改學習率。訓練完成後應呼叫 step。
此類具有論文中提出的三種內建策略:
“triangular”:基本三角週期,沒有幅度縮放。
“triangular2”:基本三角週期,每個週期將初始幅度減半。
“exp_range”:一個週期,透過 在每個週期迭代時縮放初始幅度。
此實現改編自 github 倉庫: bckenstler/CLR
- 引數
optimizer (Optimizer) – 包裝的最佳化器。
max_lr (float 或 list) – 每個引數組在週期中的上學習率邊界。功能上,它定義了週期幅度 (max_lr - base_lr)。任何週期的學習率是 base_lr 和幅度某種縮放的總和;因此,根據縮放函式,max_lr 可能實際上未達到。
step_size_up (int) – 週期遞增一半的訓練迭代次數。預設值:2000
step_size_down (int) – 週期遞減一半的訓練迭代次數。如果 step_size_down 為 None,則設定為 step_size_up。預設值:None
mode (str) – {triangular, triangular2, exp_range} 中的一個。值對應於上面詳述的策略。如果 scale_fn 不為 None,則忽略此引數。預設值:'triangular'
gamma (float) – “exp_range” 縮放函式中的常數:gamma**(cycle iterations) 預設值:1.0
scale_fn (function) – 自定義縮放策略,由一個引數的 lambda 函式定義,對於所有 x >= 0,0 <= scale_fn(x) <= 1。如果指定,則忽略 'mode'。預設值:None
scale_mode (str) – {‘cycle’, ‘iterations’}。定義 scale_fn 是基於週期數還是週期迭代次數(自週期開始以來的訓練迭代次數)進行評估。預設值:‘cycle’
cycle_momentum (bool) – 如果為
True,則動量在 'base_momentum' 和 'max_momentum' 之間與學習率成反比迴圈。預設值:Truebase_momentum (float 或 list) – 每個引數組在週期中的下動量邊界。請注意,動量與學習率成反比迴圈;在週期的峰值,動量為 'base_momentum',學習率為 'max_lr'。預設值:0.8
max_momentum (float 或 list) – 每個引數組在週期中的上動量邊界。功能上,它定義了週期幅度 (max_momentum - base_momentum)。任何週期的動量是 max_momentum 與幅度某種縮放的差值;因此,根據縮放函式,base_momentum 可能實際上未達到。請注意,動量與學習率成反比迴圈;在週期的開始,動量為 'max_momentum',學習率為 'base_lr'。預設值:0.9
last_epoch (int) – 最後一個 batch 的索引。此引數用於恢復訓練任務。由於 step() 應在每個 batch 之後呼叫,而不是在每個 epoch 之後呼叫,因此此數字代表計算出的總 batch 數,而不是計算出的總 epoch 數。當 last_epoch=-1 時,排程器從頭開始。預設值:-1
示例
>>> optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9) >>> scheduler = torch.optim.lr_scheduler.CyclicLR( ... optimizer, ... base_lr=0.01, ... max_lr=0.1, ... step_size_up=10, ... ) >>> data_loader = torch.utils.data.DataLoader(...) >>> for epoch in range(10): >>> for batch in data_loader: >>> train_batch(...) >>> scheduler.step()
- get_lr()[source]#
計算 batch 索引處的學習率。
此函式將 self.last_epoch 視為最後一個 batch 索引。
如果 self.cycle_momentum 為
True,則此函式具有更新最佳化器動量的副作用。
