MultiStepLR#
- class torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)[source]#
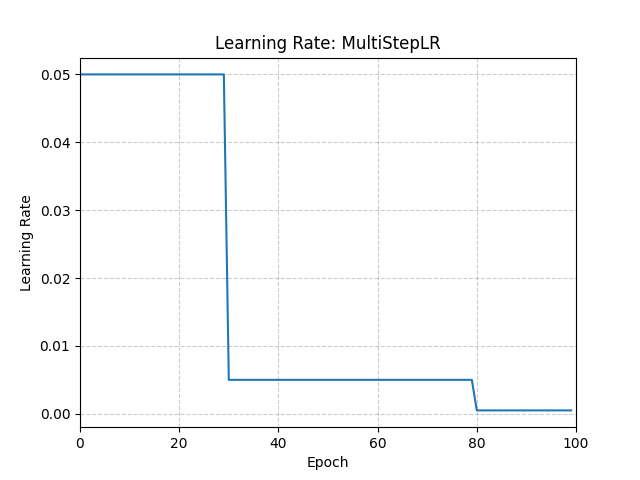
在 epoch 數達到 milestones 中的任何一個時,將每個引數組的學習率按 gamma 衰減。
請注意,這種衰減可能與此排程器之外的其他學習率變化同時發生。當 last_epoch=-1 時,將初始學習率設定為 lr。
- 引數
示例
>>> # Assuming optimizer uses lr = 0.05 for all groups >>> # lr = 0.05 if epoch < 30 >>> # lr = 0.005 if 30 <= epoch < 80 >>> # lr = 0.0005 if epoch >= 80 >>> scheduler = MultiStepLR(optimizer, milestones=[30, 80], gamma=0.1) >>> for epoch in range(100): >>> train(...) >>> validate(...) >>> scheduler.step()
- load_state_dict(state_dict)[source]#
載入排程器的狀態。
- 引數
state_dict (dict) – 排程器狀態。應該是呼叫
state_dict()返回的物件。
