常見問題#
創建於:2025 年 6 月 16 日 | 最後更新於:2025 年 6 月 16 日
torch.compile 支援訓練嗎?#
torch.compile 支援訓練,它使用 AOTAutograd 來捕獲反向傳播。
.forward()圖和optimizer.step()由 TorchDynamo 的 Pythonevalframe前端捕獲。對於 torchdynamo 捕獲的每個
.forward()片段,它使用 AOTAutograd 生成一個反向傳播圖片段。每個前向和後向圖對(可選地)透過最小割進行分割槽,以在訓練前向和後向之間儲存最小狀態。
前向和後向對被包裝在
autograd.function模組中。使用者呼叫
.backward()的程式碼仍然會觸發 eager 的 autograd 引擎,該引擎將每個*已編譯的反向傳播*圖作為一個操作來執行,同時也會執行任何未編譯的 eager 操作的.backward()函式。
您是否支援分散式程式碼?#
torch.compile 支援 DistributedDataParallel (DDP)。其他分散式訓練庫的支援正在考慮中。
分散式程式碼與 dynamo 互動具有挑戰性的主要原因在於,AOTAutograd 會展開前向和後向傳播,併為後端最佳化提供兩個圖。這對於分散式程式碼來說是個問題,因為我們希望理想情況下能夠將通訊操作與計算重疊。Eager PyTorch 透過多種方式實現這一點,例如 DDP/FSDP,透過 autograd hook、module hook 以及模組狀態的修改/突變。在 naive 應用 dynamo 的情況下,由於 AOTAutograd 編譯函式與 dispatch hook 的互動方式,本應在反向傳播過程中緊隨操作執行的 hook 可能會被延遲到整個已編譯的反向傳播操作區域之後。
最佳化 DDP 與 Dynamo 的基本策略在 distributed.py 中進行了概述,其主要思想是在 DDP bucket 邊界 上進行圖拆分。
當 DDP 中的每個節點需要與其節點同步權重時,它會將其梯度和引數組織成 buckets,這可以減少通訊時間,並允許節點廣播其一部分梯度給其他等待的節點。
分散式程式碼中的圖拆分意味著您可以期望 dynamo 及其後端能夠最佳化分散式程式的計算開銷,但無法最佳化其通訊開銷。圖拆分可能會干擾編譯加速,因為減少的圖大小會剝奪編譯器融合的機會。然而,隨著圖大小的增加,收益會遞減,因為當前大多數計算最佳化都是區域性融合。所以實際上這種方法可能就足夠了。
我還需要匯出整個圖嗎?#
對於絕大多數模型,您可能不需要,並且可以按原樣使用 torch.compile。但有些情況需要完整的圖,您可以透過簡單地執行 torch.compile(..., fullgraph=True) 來確保完整的圖。這些情況包括:
大規模訓練執行,例如 250K+,需要流水線並行和其他高階分片策略。
推理最佳化器,如 TensorRT 或 AITemplate,它們依賴於比訓練最佳化器更激進的融合。
移動端訓練或推理。
未來的工作將包括將通訊操作跟蹤到圖中,協調這些操作與計算最佳化,以及最佳化通訊操作。
為什麼我的程式碼崩潰了?#
如果您的程式碼在未啟用 torch.compile 時執行正常,但在啟用它後開始崩潰,那麼最重要的第一步是確定故障發生在堆疊的哪個部分。為了解決這個問題,請按照以下步驟操作,並且僅在前一個步驟成功後嘗試下一步。
torch.compile(..., backend="eager")僅執行 TorchDynamo 前向圖捕獲,然後使用 PyTorch 執行捕獲的圖。如果這失敗了,那麼 TorchDynamo 就存在問題。torch.compile(..., backend="aot_eager")執行 TorchDynamo 捕獲前向圖,然後使用 AOTAutograd 跟蹤反向傳播圖,而無需任何額外的後端編譯器步驟。然後,PyTorch eager 將用於執行前向和後向圖。如果這失敗了,那麼 AOTAutograd 就存在問題。torch.compile(..., backend="inductor")執行 TorchDynamo 捕獲前向圖,然後使用 AOTAutograd 跟蹤反向傳播圖,並使用 TorchInductor 編譯器。如果這失敗了,那麼 TorchInductor 就存在問題。
為什麼編譯很慢?#
Dynamo 編譯— TorchDynamo 內建了一個統計函式,用於收集和顯示每個編譯階段花費的時間。這些統計資訊可以透過在執行
torch._dynamo後呼叫torch._dynamo.utils.compile_times()來訪問。預設情況下,它會返回一個按名稱列出 TorchDynamo 各函式所花費編譯時間的字串表示。Inductor 編譯— TorchInductor 具有內建的統計和跟蹤函式,用於顯示每個編譯階段所花費的時間、輸出程式碼、輸出圖視覺化和 IR dump。
env TORCH_COMPILE_DEBUG=1 python repro.py。這是一個除錯工具,旨在幫助您更容易地除錯/理解 TorchInductor 的內部機制,其輸出將類似於 此。該除錯跟蹤中的每個檔案都可以透過torch._inductor.config.trace.*啟用/停用。由於剖析圖和圖表的生成成本很高,因此它們預設是停用的。請參閱 示例除錯目錄輸出 以獲取更多示例。過度重新編譯 當 TorchDynamo 編譯一個函式(或其一部分)時,它會針對區域性變數和全域性變數做出某些假設,以允許編譯器進行最佳化,並將這些假設表示為在執行時檢查特定值的 guards。如果任何 guard 失敗,Dynamo 將最多重新編譯該函式(或其一部分)
torch._dynamo.config.recompile_limit次。如果您的程式達到了快取限制,您首先需要確定是哪個 guard 失敗了,以及是您程式的哪一部分觸發了它。使用TORCH_TRACE/tlparse或TORCH_LOGS=recompiles來跟蹤問題的根源,有關更多詳細資訊,請參閱 torch.compile 故障排除。
為什麼我在生產環境中進行重新編譯?#
在某些情況下,您可能不希望在程式預熱後出現意外的編譯。例如,如果您在一個對延遲敏感的應用程式中提供生產流量。為此,TorchDynamo 提供了一種替代模式,其中使用先前編譯的圖,但不會生成新的圖。
frozen_toy_example = dynamo.run(toy_example)
frozen_toy_example(torch.randn(10), torch.randn(10))
您是如何加快我的程式碼的?#
加速 PyTorch 程式碼主要有三種方式:
透過垂直融合實現核心融合,它融合了順序操作以避免過多的讀/寫。例如,融合兩個連續的餘弦函式意味著您可以執行 1 次讀、1 次寫,而不是 2 次讀、2 次寫。水平融合:最簡單的例子是批處理,其中單個矩陣與一系列示例相乘,但更通用的場景是分組 GEMM,其中一組矩陣乘法被排程在一起。
無序執行:編譯器的一種通用最佳化,透過提前檢視圖中的確切資料依賴關係,我們可以決定執行節點的最佳時機以及哪些緩衝區可以重用。
自動工作負載放置:類似於無序執行的觀點,但透過將圖的節點與物理硬體或記憶體等資源進行匹配,我們可以設計一個合適的排程。
以上是加速 PyTorch 程式碼的通用原則,但不同的後端在最佳化方面會做出不同的權衡。例如,Inductor 首先負責融合所有可以融合的內容,然後才生成 Triton 核心。
Triton 還透過自動記憶體合併、記憶體管理和每個流多處理器內的排程來提供加速,並且已經設計用於處理分塊計算。
然而,無論您使用哪個後端,最好採用基準測試和觀察的方法,所以請嘗試使用 PyTorch Profiler,直觀地檢查生成的核心,並自己嘗試瞭解發生了什麼。
為什麼我沒有看到加速?#
圖中斷#
使用 dynamo 時看不到所需加速的主要原因是過多的圖拆分。那麼什麼是圖拆分?
給定一個程式,例如
def some_fun(x):
...
torch.compile(some_fun)(x)
...
Torchdynamo 將嘗試將 some_fun() 中的所有 torch/tensor 操作編譯成一個單一的 FX 圖,但它可能無法將所有內容捕獲到一個圖中。
對於 TorchDynamo 來說,一些圖拆分的原因是無法克服的,例如呼叫 PyTorch 以外的 C 擴充套件對 TorchDynamo 是不可見的,並且可以執行任意操作,而 TorchDynamo 無法引入必要的 guards 來確保編譯後的程式可以安全重用。
為了最大化效能,儘可能少地出現圖拆分很重要。
識別圖拆分的原因#
要識別程式中的所有圖拆分及其原因,可以使用 torch._dynamo.explain。此工具會在提供的函式上執行 TorchDynamo,並聚合遇到的圖拆分。這是一個用法示例:
import torch
import torch._dynamo as dynamo
def toy_example(a, b):
x = a / (torch.abs(a) + 1)
print("woo")
if b.sum() < 0:
b = b * -1
return x * b
explanation = dynamo.explain(toy_example)(torch.randn(10), torch.randn(10))
print(explanation)
"""
Graph Count: 3
Graph Break Count: 2
Op Count: 5
Break Reasons:
Break Reason 1:
Reason: builtin: print [<class 'torch._dynamo.variables.constant.ConstantVariable'>] False
User Stack:
<FrameSummary file foo.py, line 5 in toy_example>
Break Reason 2:
Reason: generic_jump TensorVariable()
User Stack:
<FrameSummary file foo.py, line 6 in torch_dynamo_resume_in_toy_example_at_5>
Ops per Graph:
...
Out Guards:
...
"""
要透過設定 fullgraph=True 來停用 Python 回退,從而在遇到的第一個圖拆分時丟擲錯誤。如果您使用過基於 export 的編譯器,這應該很熟悉。
def toy_example(a, b):
...
torch.compile(toy_example, fullgraph=True, backend=<compiler>)(a, b)
為什麼我更改程式碼後沒有重新編譯?#
如果您透過設定 env TORCHDYNAMO_DYNAMIC_SHAPES=1 python model.py 啟用了動態形狀,那麼您的程式碼將不會在形狀變化時重新編譯。我們添加了對動態形狀的支援,這可以在形狀變化小於 2 倍的情況下避免重新編譯。這在 CV 中的不同影像尺寸或 NLP 中的可變序列長度等場景中特別有用。在推理場景中,由於您會接收來自不同客戶端應用程式的各種請求,因此通常無法提前知道批次大小是多少。
總的來說,TorchDynamo 會盡力避免不必要的重新編譯。例如,如果 TorchDynamo 找到 3 個圖,而您的更改只修改了一個圖,那麼只會重新編譯該圖。因此,避免可能緩慢的編譯時間的另一個技巧是預熱模型,在編譯一次之後,後續的編譯會快得多。冷啟動編譯時間仍然是我們可見跟蹤的指標。
為什麼我的結果不正確?#
透過設定環境變數 TORCHDYNAMO_REPRO_LEVEL=4 也可以最小化精度問題,它的工作方式類似於 git bisect 模型,一個完整的重現可能類似於 TORCHDYNAMO_REPRO_AFTER="aot" TORCHDYNAMO_REPRO_LEVEL=4。我們需要這個是因為下游編譯器會生成程式碼,無論是 Triton 程式碼還是 C++ 後端,這些下游編譯器的數值可能存在細微差別,但對您的訓練穩定性產生巨大影響。因此,精度偵錯程式對於我們檢測程式碼生成或後端編譯器中的 bug 非常有用。
如果您想確保隨機數生成在 torch 和 triton 之間是相同的,您可以啟用 torch._inductor.config.fallback_random = True。
為什麼我會遇到 OOM?#
Dynamo 仍處於 alpha 階段,因此存在一些 OOM 的來源。如果您遇到 OOM,請嘗試按順序停用以下配置,然後開啟一個 GitHub issue,以便我們解決根本問題:1. 如果您正在使用動態形狀,請嘗試停用它們,我們預設停用了它們:env TORCHDYNAMO_DYNAMIC_SHAPES=0 python model.py 2. Triton 中的 CUDA 圖在 inductor 中是預設啟用的,但停用它們可能會緩解一些 OOM 問題:torch._inductor.config.triton.cudagraphs = False。
torch.func 是否與 torch.compile 一起使用(用於 grad 和 vmap 轉換)?#
將 torch.func 轉換應用於使用 torch.compile 的函式是可行的。
import torch
@torch.compile
def f(x):
return torch.sin(x)
def g(x):
return torch.grad(f)(x)
x = torch.randn(2, 3)
g(x)
在由 torch.compile 處理的函式內部呼叫 torch.func 轉換#
使用 torch.compile 編譯 torch.func.grad#
import torch
def wrapper_fn(x):
return torch.func.grad(lambda x: x.sin().sum())(x)
x = torch.randn(3, 3, 3)
grad_x = torch.compile(wrapper_fn)(x)
使用 torch.compile 編譯 torch.vmap#
import torch
def my_fn(x):
return torch.vmap(lambda x: x.sum(1))(x)
x = torch.randn(3, 3, 3)
output = torch.compile(my_fn)(x)
編譯不受支援的函式(逃生艙)#
對於其他轉換,作為一種解決方法,請使用 torch._dynamo.allow_in_graph。
allow_in_graph 是一個逃生艙。如果您的程式碼無法使用檢查 Python 位元組碼的 torch.compile 工作,但您認為它可以透過符號跟蹤方法(如 jax.jit)工作,則使用 allow_in_graph。
透過使用 allow_in_graph 註釋一個函式,您必須確保您的程式碼滿足以下要求:
您的函式中的所有輸出僅取決於輸入,而不取決於任何捕獲的 Tensor。
您的函式是函式式的。也就是說,它不會修改任何狀態。這可能會放寬;實際上,我們支援從外部看起來是函式式的函式:它們可能有就地 PyTorch 操作,但不能修改全域性狀態或函式的輸入。
您的函式不會引發資料相關的錯誤。
import torch
@torch.compile
def f(x):
return torch._dynamo.allow_in_graph(torch.vmap(torch.sum))(x)
x = torch.randn(2, 3)
f(x)
一個常見的陷阱是使用 allow_in_graph 來註釋呼叫 nn.Module 的函式。這是因為輸出現在取決於 nn.Module 的引數。要使此工作,請使用 torch.func.functional_call 來提取模組狀態。
NumPy 是否與 torch.compile 一起使用?#
從 2.1 版本開始,torch.compile 可以理解原生 NumPy 程式(作用於 NumPy 陣列)以及混合 PyTorch-NumPy 程式(透過 x.numpy()、torch.from_numpy 和相關函式在 PyTorch 和 NumPy 之間進行轉換)。
torch.compile 支援哪些 NumPy 功能?#
torch.compile 中的 NumPy 遵循 NumPy 2.0 預釋出版本。
通常,torch.compile 能夠跟蹤大多數 NumPy 結構,當它無法跟蹤時,它會回退到 eager 模式,並讓 NumPy 執行該程式碼片段。即便如此,在少數功能上,torch.compile 的語義與 NumPy 的略有不同:
NumPy 標量:我們將其建模為 0 維陣列。也就是說,在
torch.compile下,np.float32(3)返回一個 0 維陣列。為了避免圖拆分,最好使用這個 0 維陣列。如果這破壞了您的程式碼,您可以透過將 NumPy 標量轉換為相關的 Python 標量型別(bool/int/float)來解決此問題。負步長:
np.flip和帶有負步長的切片會返回副本。型別提升:NumPy 的型別提升將在 NumPy 2.0 中發生變化。新規則在 NEP 50 中進行了描述。
torch.compile實現的是 NEP 50,而不是當前即將棄用的規則。{tril,triu}_indices_from/{tril,triu}_indices返回陣列而不是陣列元組。
還有其他一些功能我們不支援跟蹤,並且我們優雅地回退到 NumPy 來執行它們:
非數字 dtype,如日期時間、字串、字元、void、結構化 dtype 和 recarrays。
長 dtype
np.float128/np.complex256和一些無符號 dtypenp.uint16/np.uint32/np.uint64。ndarray子類。掩碼陣列。
晦澀的 ufunc 機制,如
axes=[(n,k),(k,m)->(n,m)]和 ufunc 方法(例如np.add.reduce)。對
complex64/complex128陣列進行排序/排序。NumPy
np.poly1d和np.polynomial。具有 2 個或更多返回值的函式中的位置引數
out1, out2(out=tuple是有效的)。__array_function__、__array_interface__和__array_wrap__。ndarray.ctypes屬性。
我可以使用 torch.compile 編譯 NumPy 程式碼嗎?#
當然可以!torch.compile 可以原生理解 NumPy 程式碼,並將其視為 PyTorch 程式碼。要做到這一點,只需用 torch.compile 裝飾器包裝 NumPy 程式碼即可。
import torch
import numpy as np
@torch.compile
def numpy_fn(X: np.ndarray, Y: np.ndarray) -> np.ndarray:
return np.sum(X[:, :, None] * Y[:, None, :], axis=(-2, -1))
X = np.random.randn(1024, 64)
Y = np.random.randn(1024, 64)
Z = numpy_fn(X, Y)
assert isinstance(Z, np.ndarray)
使用環境變數 TORCH_LOGS=output_code 執行此示例,我們可以看到 torch.compile 能夠將乘法和求和融合到一個 C++ 核心中。它還可以使用 OpenMP 並行執行它們(原生 NumPy 是單執行緒的)。這可以輕鬆地使您的 NumPy 程式碼比原來快 n 倍,其中 n 是您處理器上的核心數!
以這種方式跟蹤 NumPy 程式碼也支援編譯程式碼中的圖拆分。
我可以在 CUDA 上執行 NumPy 程式碼並透過 torch.compile 計算梯度嗎?#
是的,您可以!要做到這一點,您只需在 torch.device("cuda") 上下文中執行程式碼。考慮以下示例:
import torch
import numpy as np
@torch.compile
def numpy_fn(X: np.ndarray, Y: np.ndarray) -> np.ndarray:
return np.sum(X[:, :, None] * Y[:, None, :], axis=(-2, -1))
X = np.random.randn(1024, 64)
Y = np.random.randn(1024, 64)
with torch.device("cuda"):
Z = numpy_fn(X, Y)
assert isinstance(Z, np.ndarray)
在此示例中,numpy_fn 將在 CUDA 上執行。為了實現這一點,torch.compile 會自動將 X 和 Y 從 CPU 移動到 CUDA,然後將結果 Z 從 CUDA 移動到 CPU。如果我們多次在同一程式執行中執行此函式,我們可能希望避免所有這些相當昂貴的記憶體副本。要做到這一點,我們只需調整我們的 numpy_fn,使其能夠接受 CUDA Tensor 並返回 Tensor。我們可以透過使用 torch.compiler.wrap_numpy 來實現這一點。
@torch.compile(fullgraph=True)
@torch.compiler.wrap_numpy
def numpy_fn(X, Y):
return np.sum(X[:, :, None] * Y[:, None, :], axis=(-2, -1))
X = torch.randn(1024, 64, device="cuda")
Y = torch.randn(1024, 64, device="cuda")
Z = numpy_fn(X, Y)
assert isinstance(Z, torch.Tensor)
assert Z.device.type == "cuda"
在這裡,我們顯式地在 CUDA 記憶體中建立 Tensor,並將它們傳遞給函式,該函式在 CUDA 裝置上執行所有計算。wrap_numpy 負責將任何 torch.Tensor 輸入標記為具有 np.ndarray 語義的輸入,在 torch.compile 級別。在編譯器中標記 Tensor 是一個非常便宜的操作,因此在執行時不會發生資料複製或資料移動。
使用此裝飾器,我們還可以區分 NumPy 程式碼!
@torch.compile(fullgraph=True)
@torch.compiler.wrap_numpy
def numpy_fn(X, Y):
return np.mean(np.sum(X[:, :, None] * Y[:, None, :], axis=(-2, -1)))
X = torch.randn(1024, 64, device="cuda", requires_grad=True)
Y = torch.randn(1024, 64, device="cuda")
Z = numpy_fn(X, Y)
assert isinstance(Z, torch.Tensor)
Z.backward()
# X.grad now holds the gradient of the computation
print(X.grad)
我們一直在使用 fullgraph=True,因為在這種情況下,圖拆分是有問題的。當發生圖拆分時,我們需要具體化 NumPy 陣列。由於 NumPy 陣列沒有 device 或 requires_grad 的概念,因此在圖拆分期間會丟失此資訊。
我們無法透過圖拆分傳播梯度,因為圖拆分程式碼可能會執行任意程式碼,而這些程式碼不知道如何進行區分。另一方面,在 CUDA 執行的情況下,我們可以透過使用 torch.device("cuda") 上下管理器來解決這個問題,就像我們在第一個示例中所做的那樣。
@torch.compile
@torch.compiler.wrap_numpy
def numpy_fn(X, Y):
prod = X[:, :, None] * Y[:, None, :]
print("oops, a graph break!")
return np.sum(prod, axis=(-2, -1))
X = torch.randn(1024, 64, device="cuda")
Y = torch.randn(1024, 64, device="cuda")
with torch.device("cuda"):
Z = numpy_fn(X, Y)
assert isinstance(Z, torch.Tensor)
assert Z.device.type == "cuda"
在圖拆分期間,中間 Tensor 仍然需要移動到 CPU,但在圖拆分後恢復跟蹤時,圖的其餘部分仍然在 CUDA 上進行跟蹤。考慮到這種 CUDA <> CPU 和 CPU <> CUDA 的移動,圖拆分在 NumPy 上下文中相當昂貴,應該避免,但至少它們允許跟蹤複雜的程式碼片段。
如何在 torch.compile 下除錯 NumPy 程式碼?#
除錯 JIT 編譯程式碼具有挑戰性,考慮到現代編譯器的複雜性以及它們引發的令人畏懼的錯誤。 torch.compile 故障排除文件 包含一些解決此任務的技巧。
如果以上不足以確定問題的根源,我們仍然可以使用一些其他的 NumPy 特定工具。我們可以透過停用對 NumPy 函式的跟蹤來區分 PyTorch 程式碼中是否存在 bug:
from torch._dynamo import config
config.trace_numpy = False
如果 bug 出在跟蹤的 NumPy 程式碼中,我們可以透過匯入 import torch._numpy as np 來使用 PyTorch 作為後端,以 eager 模式(無需 torch.compile)執行 NumPy 程式碼。這僅應用於除錯目的,絕不能替代 PyTorch API,因為它效能差很多,並且作為私有 API,可能會在未通知的情況下更改。無論如何,torch._numpy 是 PyTorch 的 NumPy Python 實現,它被 torch.compile 內部用於將 NumPy 程式碼轉換為 PyTorch 程式碼。它相對容易閱讀和修改,因此如果您發現任何 bug,請隨時提交 PR 進行修復或直接開啟 issue。
如果匯入 torch._numpy as np 後程序可以正常工作,那麼 bug 很可能在 TorchDynamo 中。如果是這種情況,請隨時開啟一個 issue,並附帶一個 最小可重現示例。
我使用 torch.compile 編譯了一些 NumPy 程式碼,但沒有看到任何加速。#
最好的起點是 關於如何除錯此類 torch.compile 問題的通用建議教程。
一些圖拆分可能是由於使用了不受支援的功能。請參閱 torch.compile 支援哪些 NumPy 功能?。更一般地說,牢記一些廣泛使用的 NumPy 功能與編譯器配合不佳。例如,就地修改使編譯器中的推理變得困難,並且通常會產生比其異地對應版本差的效能。因此,最好避免它們。同樣適用於使用 out= 引數。相反,請優先使用異地操作,讓 torch.compile 最佳化記憶體使用。同樣的情況也適用於資料依賴操作,如透過布林掩碼進行的掩碼索引,或資料依賴控制流,如 if 或 while 結構。
用於細粒度跟蹤的 API 是什麼?#
在某些情況下,您可能需要將程式碼的小部分排除在 torch.compile 編譯之外。本節提供了一些答案,您可以在 用於細粒度跟蹤的 TorchDynamo API 中找到更多資訊。
如何對函式進行圖拆分?#
對函式進行圖拆分不足以充分表達您希望 PyTorch 執行的操作。您需要更具體地說明您的用例。一些最常見的用例可能需要您考慮:
如果您想停用此函式幀及其遞迴呼叫的幀的編譯,請使用
torch._dynamo.disable。如果您希望某個特定的運算子(例如
fbgemm)使用 eager 模式,請使用torch._dynamo.disallow_in_graph。
一些不常見的用例包括:
如果您想停用函式幀上的 TorchDynamo,但在遞迴呼叫的幀上重新啟用它——請使用
torch._dynamo.disable(recursive=False)。如果您想阻止行內函數幀——請在您想要阻止內聯的函式開頭使用
torch._dynamo.graph_break。
torch._dynamo.disable 和 torch._dynamo.disallow_in_graph 之間有什麼區別?#
Disallow-in-graph 在運算子級別工作,或者更具體地說,在 TorchDynamo 提取的圖中看到的運算子級別工作。
Disable 在函式幀級別工作,並決定 TorchDynamo 是否應該檢視函式幀。
torch._dynamo.disable 和 torch._dynamo_skip 之間有什麼區別?#
注意
torch._dynamo_skip 已棄用。
您最有可能需要 torch._dynamo.disable。但在不太可能的情況下,您可能需要更精細地控制。假設您只想停用 a_fn 函式上的跟蹤,但希望在 aa_fn 和 ab_fn 中繼續跟蹤。下圖演示了此用例:
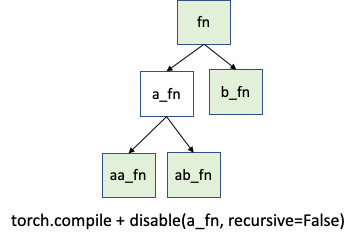
在這種情況下,您可以使用 torch._dynamo.disable(recursive=False)。在以前的版本中,此功能由 torch._dynamo.skip 提供。現在,這由 torch._dynamo.disable 中的 recursive 標誌支援。
