理解基於 TorchDynamo 的 ONNX 匯出器記憶體使用情況#
建立時間:2024年11月06日 | 最後更新時間:2025年06月18日
以前的基於 TorchScript 的 ONNX 匯出器會執行模型一次以追蹤其執行,這可能導致在 GPU 記憶體不足的情況下模型耗盡 GPU 記憶體。這個問題已透過新的基於 TorchDynamo 的 ONNX 匯出器得到解決。
基於 TorchDynamo 的 ONNX 匯出器利用 torch.export.export() 函式來利用 FakeTensorMode,從而避免在匯出過程中執行實際的張量計算。與基於 TorchScript 的 ONNX 匯出器相比,這種方法可以顯著降低記憶體使用量。
下面是一個示例,展示了基於 TorchScript 和基於 TorchDynamo 的 ONNX 匯出器之間的記憶體使用差異。在此示例中,我們使用了 MONAI 的 HighResNet 模型。在繼續之前,請從 PyPI 安裝它。
pip install monai
PyTorch 提供了一個捕獲和視覺化記憶體使用軌跡的工具。我們將使用此工具在匯出過程中記錄兩個匯出器的記憶體使用情況並進行比較。您可以在 理解 CUDA 記憶體使用情況 上找到有關此工具的更多詳細資訊。
基於 TorchScript 的匯出器#
可以執行以下程式碼來生成一個快照檔案,該檔案記錄了匯出過程中分配的 CUDA 記憶體狀態。
import torch
from monai.networks.nets import (
HighResNet,
)
torch.cuda.memory._record_memory_history()
model = HighResNet(
spatial_dims=3, in_channels=1, out_channels=3, norm_type="batch"
).eval()
model = model.to("cuda")
data = torch.randn(30, 1, 48, 48, 48, dtype=torch.float32).to("cuda")
with torch.no_grad():
onnx_program = torch.onnx.export(
model,
data,
"torchscript_exporter_highresnet.onnx",
dynamo=False,
)
snapshot_name = "torchscript_exporter_example.pickle"
print(f"generate {snapshot_name}")
torch.cuda.memory._dump_snapshot(snapshot_name)
print("Export is done.")
開啟 pytorch.org/memory_viz 並將生成的 pickle 快照檔案拖放到視覺化工具中。記憶體使用情況如下所示:
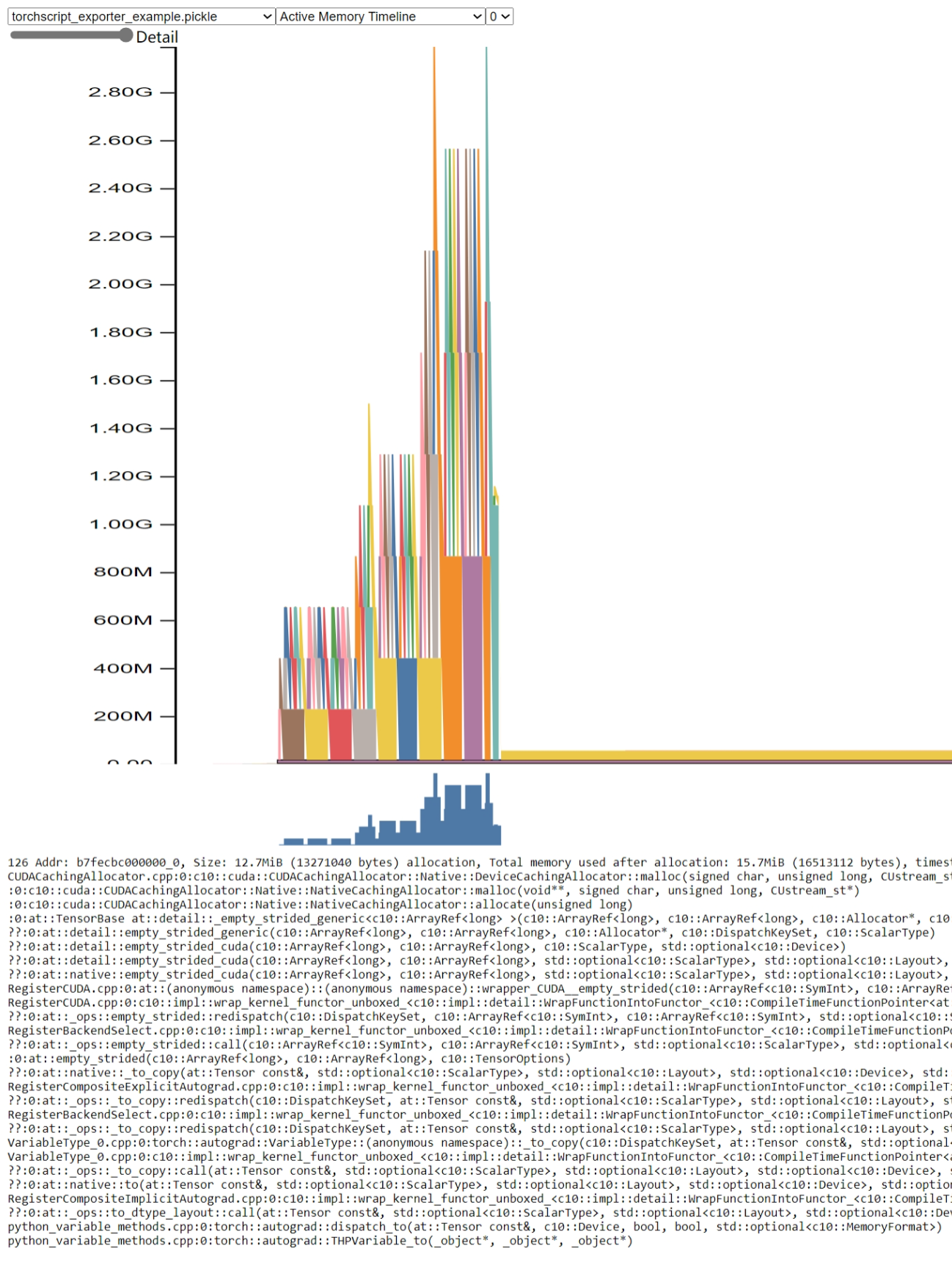
從圖中可以看出,記憶體使用峰值高於 2.8 GB。
基於 TorchDynamo 的匯出器#
可以執行以下程式碼來生成一個快照檔案,該檔案記錄了匯出過程中分配的 CUDA 記憶體狀態。
import torch
from monai.networks.nets import (
HighResNet,
)
torch.cuda.memory._record_memory_history()
model = HighResNet(
spatial_dims=3, in_channels=1, out_channels=3, norm_type="batch"
).eval()
model = model.to("cuda")
data = torch.randn(30, 1, 48, 48, 48, dtype=torch.float32).to("cuda")
with torch.no_grad():
onnx_program = torch.onnx.export(
model,
data,
"test_faketensor.onnx",
dynamo=True,
)
snapshot_name = f"torchdynamo_exporter_example.pickle"
print(f"generate {snapshot_name}")
torch.cuda.memory._dump_snapshot(snapshot_name)
print(f"Export is done.")
開啟 pytorch.org/memory_viz 並將生成的 pickle 快照檔案拖放到視覺化工具中。記憶體使用情況如下所示:
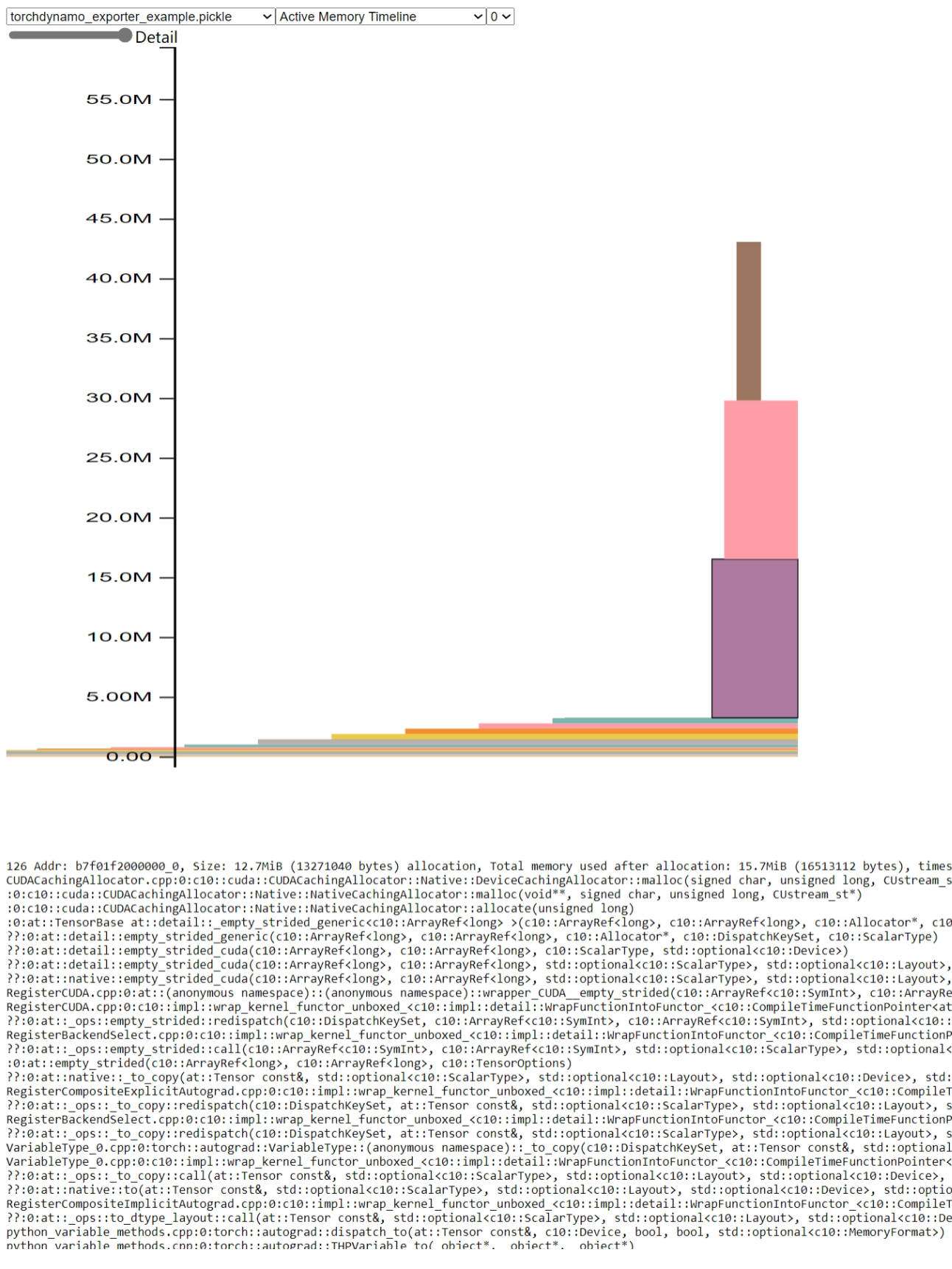
從圖中可以看出,記憶體使用峰值僅為 45MB 左右。與基於 TorchScript 的匯出器的記憶體使用峰值相比,記憶體使用量減少了 98%。