草稿匯出#
創建於: 2025年6月13日 | 最後更新於: 2025年6月13日
警告
此功能不適用於生產環境,而是作為除錯 torch.export 跟蹤錯誤的工具。
草稿匯出是匯出功能的新版本,旨在始終生成圖,即使可能存在健全性問題,並生成一個報告,列出匯出在跟蹤過程中遇到的所有問題並提供其他除錯資訊。對於沒有假核心的自定義運算子,它還將生成一個配置檔案,您可以註冊該檔案以自動生成假核心。
您是否曾經嘗試使用 torch.export.export() 匯出模型,結果卻遇到與資料相關的錯誤?修復了該問題,但又遇到了缺少假核心的問題。解決該問題後,您又遇到了另一個與資料相關的錯誤。您可能會想,我真希望有一種方法可以讓我得到一個圖來玩,並且能夠在一個地方看到所有問題,以便以後修復它們……
draft_export 來拯救你!
draft_export 是匯出功能的一個版本,它將始終成功匯出圖,即使可能存在健全性問題。然後,這些問題將被編譯成報告,以便更清晰地視覺化,並可以稍後修復。
它是如何工作的?#
在正常匯出中,我們會將示例輸入轉換為 FakeTensors,並使用它們來記錄操作並將程式跟蹤到圖中。可變形狀的輸入張量(透過 dynamic_shapes 標記)或張量中的值(通常來自 .item() 呼叫)將表示為符號形狀 (SymInt),而不是具體整數。但是,在跟蹤過程中可能會出現一些問題 - 我們可能會遇到無法評估的守衛,例如,如果我們想檢查張量中的某個項是否大於 0 (u0 >= 0)。由於跟蹤器對 u0 的值一無所知,它將丟擲與資料相關的錯誤。如果模型使用了自定義運算子但沒有為它定義假核心,那麼我們將因 fake_tensor.UnsupportedOperatorException 而出錯,因為匯出不知道如何將其應用於 FakeTensors。如果自定義運算子的假核心實現不正確,匯出將默默地生成一個與急切行為不匹配的錯誤圖。
為了修復上述錯誤,草稿匯出使用 *真實張量跟蹤* 來指導我們如何繼續跟蹤。當我們使用假張量跟蹤模型時,對於在假張量上發生的每個操作,草稿匯出還將使用儲存的真實張量來執行該運算子,這些真實張量來自傳遞給匯出的示例輸入。這使我們能夠解決上述錯誤:當我們遇到無法評估的守衛時,例如 u0 >= 0,我們將使用儲存的真實張量值來評估該守衛。執行時斷言將被新增到圖中,以確保圖斷言與我們在跟蹤時假設的相同守衛。如果我們遇到一個沒有假核心的自定義運算子,我們將使用儲存的真實張量來執行該運算子的正常核心,並返回一個具有相同等級但形狀未繫結的假張量。由於我們擁有每個操作的真實張量輸出,我們將此與假核心的假張量輸出進行比較。如果假核心實現不正確,我們將捕獲此行為並生成一個更正確的假核心。
如何使用草稿匯出?#
假設您正在嘗試匯出以下程式碼:
class M(torch.nn.Module):
def forward(self, x, y, z):
res = torch.ops.mylib.foo2(x, y)
a = res.item()
a = -a
a = a // 3
a = a + 5
z = torch.cat([z, z])
torch._check_is_size(a)
torch._check(a < z.shape[0])
return z[:a]
inp = (torch.tensor(3), torch.tensor(4), torch.ones(3, 3))
ep = torch.export.export(M(), inp)
這會導致 mylib.foo2 的“缺少假核心”錯誤,然後是由於使用未繫結的符號整數 a 對 z 進行切片而導致的 GuardOnDataDependentExpression。
要呼叫 draft-export,我們可以將 torch.export 行替換為以下內容:
ep = torch.export.draft_export(M(), inp)
ep 是一個有效的 ExportedProgram,現在可以傳遞給其他環境!
使用草稿匯出進行除錯#
在草稿匯出的終端輸出中,您應該會看到以下訊息:
#########################################################################################
WARNING: 2 issue(s) found during export, and it was not able to soundly produce a graph.
To view the report of failures in an html page, please run the command:
`tlparse /tmp/export_angelayi/dedicated_log_torch_trace_axpofwe2.log --export`
Or, you can view the errors in python by inspecting `print(ep._report)`.
########################################################################################
草稿匯出會自動轉儲 tlparse 的日誌。您可以透過 print(ep._report) 檢視跟蹤錯誤,或者將日誌傳遞給 tlparse 以生成 HTML 報告。
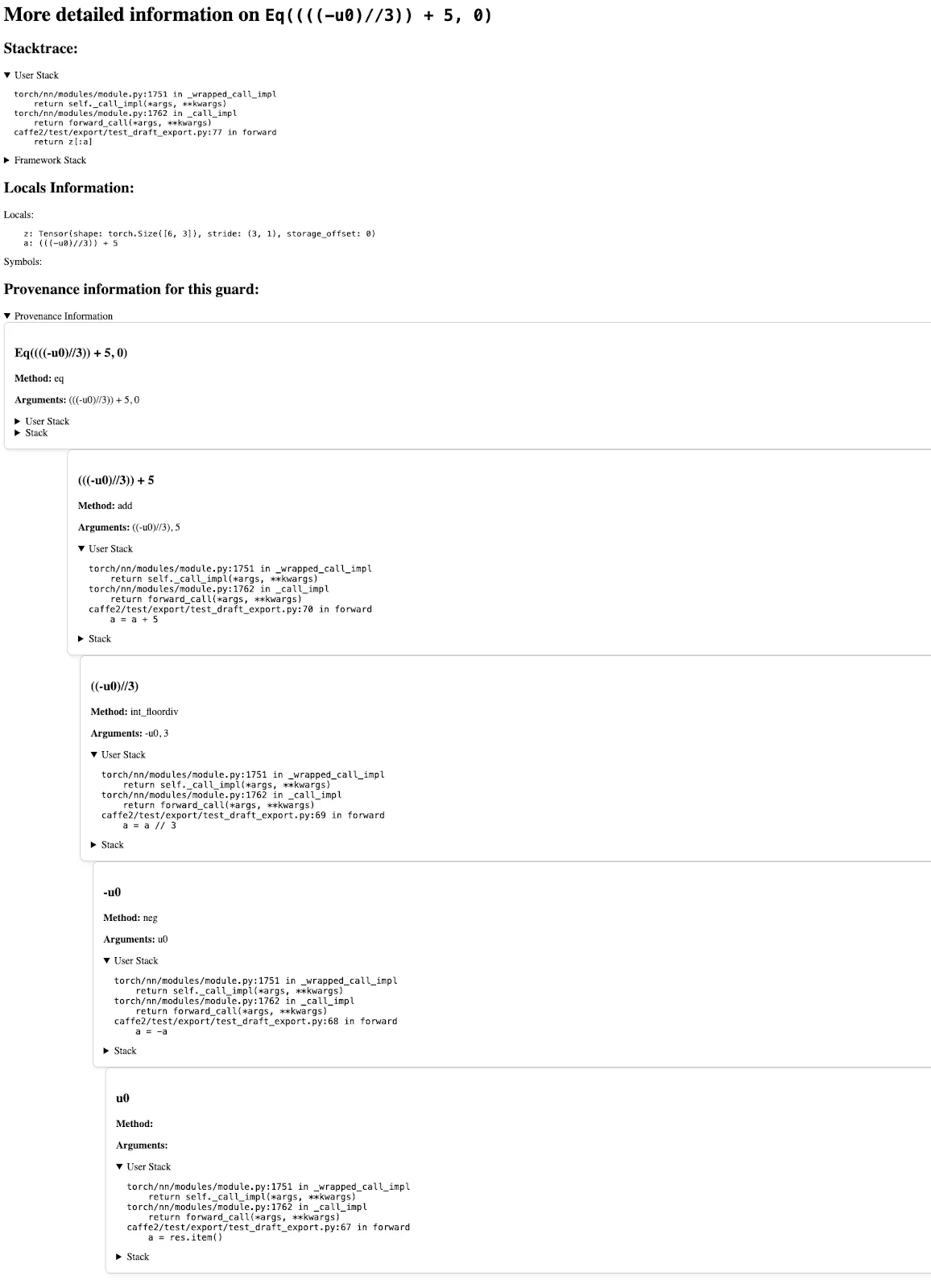
在終端執行 tlparse 命令將生成一個 tlparse HTML 報告。下面是一個 tlparse 報告的示例。

點選“與資料相關的錯誤”,我們將看到以下頁面,其中包含幫助除錯此錯誤的資訊。具體來說,它包含:
發生此錯誤的堆疊跟蹤
本地變數及其形狀列表
關於此守衛如何建立的資訊
返回的 Exported Program#
由於草稿匯出基於示例輸入對程式碼路徑進行特化,因此透過草稿匯出生成的 Exported Program 保證至少對於給定的示例輸入是可執行的並且能返回正確的結果。其他輸入也可以工作,只要它們匹配我們草稿匯出時所採取的相同守衛。
例如,如果我們有一個基於值大於 5 的圖分支,如果在草稿匯出中我們的示例輸入大於 5,那麼返回的 ExportedProgram 將特化到該分支,並斷言該值大於 5。這意味著程式將在您傳入另一個大於 5 的值時成功,但在您傳入小於 5 的值時會失敗。這比 torch.jit.trace 更可靠,後者會默默地特化到該分支。對於 torch.export 支援兩個分支的正確方法是使用 torch.cond 重寫程式碼,該程式碼將捕獲兩個分支。
由於圖中存在執行時斷言,因此返回的 exported-program 也可以使用 torch.export 或 torch.compile 進行重跟蹤,在缺少假核心的自定義運算子的情況下需要進行少量新增。
生成假核心#
如果自定義運算子不包含假實現,目前草稿匯出將使用真實張量傳播來獲取運算子的輸出並繼續跟蹤。但是,如果我們使用假張量執行匯出的程式或重跟蹤匯出的模型,我們仍然會失敗,因為仍然沒有假核心實現。
為了解決這個問題,在草稿匯出之後,我們將為遇到的每個自定義運算子呼叫生成一個運算子配置檔案,並將其儲存在附加到匯出的程式的報告中:ep._report.op_profiles。然後,使用者可以使用上下文管理器 torch._library.fake_profile.unsafe_generate_fake_kernels 根據這些運算子配置檔案生成並註冊一個假實現。這樣,未來的假張量重跟蹤將起作用。
工作流程如下:
class M(torch.nn.Module):
def forward(self, a, b):
res = torch.ops.mylib.foo(a, b) # no fake impl
return res
ep = draft_export(M(), (torch.ones(3, 4), torch.ones(3, 4)))
with torch._library.fake_profile.unsafe_generate_fake_kernels(ep._report.op_profiles):
decomp = ep.run_decompositions()
new_inp = (
torch.ones(2, 3, 4),
torch.ones(2, 3, 4),
)
# Save the profile to a yaml and check it into a codebase
save_op_profiles(ep._report.op_profiles, "op_profile.yaml")
# Load the yaml
loaded_op_profile = load_op_profiles("op_profile.yaml")
運算子配置檔案是一個將運算子名稱對映到一組配置檔案的字典,這些配置檔案描述了運算子的輸入和輸出,並且可以手動編寫、儲存到 yaml 檔案中,然後檢入程式碼庫。以下是 mylib.foo.default 的配置檔案示例:
"mylib.foo.default": {
OpProfile(
args_profile=(
TensorMetadata(
rank=2,
dtype=torch.float32,
device=torch.device("cpu"),
layout=torch.strided,
),
TensorMetadata(
rank=2,
dtype=torch.float32,
device=torch.device("cpu"),
layout=torch.strided,
),
),
out_profile=TensorMetadata(
rank=2,
dtype=torch.float32,
device=torch.device("cpu"),
layout=torch.strided,
),
)
}
mylib.foo.default 的配置檔案僅包含一個配置,該配置說明對於兩個秩為 2、資料型別為 torch.float32、裝置為 cpu 的輸入張量,我們將返回一個秩為 2、資料型別為 torch.float32、裝置為 cpu 的輸出張量。使用上下文管理器,然後將生成一個偽造的核心,該核心接收兩個秩為 2 的輸入張量(以及其他張量元資料),並輸出一個秩為 2 的張量(以及其他張量元資料)。
如果該運算元還支援其他輸入秩,我們可以將該配置新增到此配置列表中,方法是手動新增到現有配置中,或者使用新的輸入重新執行 draft-export 以獲取新配置,這樣生成的偽造核心將支援更多輸入型別。否則將出錯。
接下來做什麼?#
既然我們已經使用 draft-export 成功建立了 ExportedProgram,我們可以使用 AOTInductor 等進一步的編譯器來最佳化其效能並生成可執行的產物。然後,此最佳化版本可用於部署。同時,我們可以利用 draft-export 生成的報告來識別和修復遇到的 torch.export 錯誤,以便使用 torch.export 直接跟蹤原始模型。