torchrl.envs 包¶
TorchRL 提供了一個 API 來處理不同後端(如 gym、dm-control、dm-lab、基於模型的環境以及自定義環境)的環境。目標是能夠在實驗中輕鬆地(甚至無需任何努力)切換環境,即使這些環境是使用不同庫模擬的。TorchRL 在 torchrl.envs.libs 下提供了一些開箱即用的環境包裝器,我們希望這些包裝器可以輕鬆地被其他庫模仿。父類 EnvBase 是一個 torch.nn.Module 的子類,它使用 tensordict.TensorDict 作為資料組織器實現了某些典型的環境方法。這使得該類具有通用性,能夠處理任意數量的輸入和輸出,以及巢狀或批處理的資料結構。
每個環境都將具有以下屬性
env.batch_size:一個torch.Size,表示一起批處理的環境數量。env.device:輸入和輸出 tensordict 期望存在的裝置。環境裝置並不意味著實際的步進操作將在裝置上計算(這是後端的責任,TorchRL 在這方面能做的很少)。環境的裝置僅表示資料輸入或從環境中檢索時期望的裝置。TorchRL 負責將資料對映到所需的裝置。這對於轉換(見下文)特別有用。對於引數化環境(例如,基於模型的環境),裝置確實代表了將用於計算操作的硬體。env.observation_spec:一個Composite物件,包含所有觀察鍵-規格對。env.state_spec:一個Composite物件,包含所有輸入鍵-規格對(動作除外)。對於大多數有狀態環境,此容器將為空。env.action_spec:一個TensorSpec物件,表示動作規格。env.reward_spec:一個TensorSpec物件,表示獎勵規格。env.done_spec:一個TensorSpec物件,表示完成標誌規格。請參閱下面的軌跡終止部分。env.input_spec:一個Composite物件,包含所有輸入鍵("full_action_spec"和"full_state_spec")。env.output_spec:一個Composite物件,包含所有輸出鍵("full_observation_spec"、"full_reward_spec"和"full_done_spec")。
如果環境包含非張量資料,則可以使用 NonTensor 例項。
環境規格:鎖定和批次大小¶
環境規格預設是鎖定的(透過傳遞給環境建構函式的 spec_locked 引數)。鎖定規格意味著任何對規格(或其子項,如果它是 Composite 例項)的修改都需要先解鎖。這可以透過 set_spec_lock_() 來完成。規格預設被鎖定的原因是,這使得快取動作或重置鍵等值變得容易。解鎖環境僅應在預期規格會經常被修改時進行(原則上,這應該避免)。規格的修改,如 env.observation_spec = new_spec 是允許的:在幕後,TorchRL 會清除快取,解鎖規格,進行修改,並在環境先前被鎖定時重新鎖定規格。
重要的是,環境規格的形狀應包含批次大小,例如,具有 env.batch_size == torch.Size([4]) 的環境應該有一個形狀為 torch.Size([4, action_size]) 的 env.action_spec。這在預分配張量、檢查形狀一致性等方面很有用。
環境方法¶
透過這些,實現了以下方法:
env.reset():一個重置方法,可能(但不一定需要)接受一個tensordict.TensorDict輸入。它返回一個軌跡的第一個 tensordict,通常包含一個"done"狀態和一組觀察。如果不存在,“reward”鍵將被初始化為 0 和適當的形狀。env.step():一個步進方法,接受一個tensordict.TensorDict輸入,其中包含輸入動作以及其他輸入(例如,對於基於模型的或無狀態的環境)。env.step_and_maybe_reset():執行一個步進,並在需要時(部分)重置環境。它返回一個帶有"next"鍵的更新輸入,該鍵包含下一個步進的資料,以及一個包含下一個步進輸入資料的 tensordict(即,重置或結果或step_mdp())。這是透過讀取done_keys併為每個完成狀態分配一個"_reset"訊號來完成的。此方法可以輕鬆地編寫不間斷的軌跡函式。>>> data_ = env.reset() >>> result = [] >>> for i in range(N): ... data, data_ = env.step_and_maybe_reset(data_) ... result.append(data) ... >>> result = torch.stack(result)
env.set_seed():一個播種方法,將在多環境設定中返回下一個要使用的種子。此下一個種子是從前一個種子確定性計算的,這樣就可以為多個環境播種不同的種子,而不會在連續的實驗中冒種子重疊的風險,同時仍然具有可復現的結果。env.rollout():在環境中執行一個軌跡,最多max_steps=N步,並使用策略(policy=model)。策略應使用tensordict.nn.TensorDictModule(或其他tensordict.TensorDict相容模組)進行編碼。生成的tensordict.TensorDict例項將帶有尾隨的"time"命名維度,該維度可用於其他模組正確處理此批處理維度。
下圖總結了 torchrl 中軌跡的執行方式。

使用 TensorDict 的 TorchRL 軌跡。¶
簡而言之,一個 TensorDict 由 reset() 方法建立,然後由策略填充動作,再傳遞給 step() 方法,該方法在 "next" 條目下寫入觀察、完成標誌和獎勵。此呼叫的結果被儲存以供傳遞,並且 "next" 條目由 step_mdp() 函式收集。
注意
通常,所有 TorchRL 環境在其輸出 tensordict 中都有 "done" 和 "terminated" 條目。如果它們不是按設計存在的,EnvBase 元類將確保每個完成或終止都與其對偶配對。在 TorchRL 中,"done" 嚴格指所有軌跡結束訊號的並集,應解釋為“軌跡的最後一步”或等效地“需要重置的訊號”。如果環境提供它(例如,Gymnasium),截斷條目也會寫入 EnvBase.step() 輸出,並顯示在 "truncated" 條目下。如果環境包含單個值,則預設將其解釋為 "terminated" 訊號。預設情況下,TorchRL 的收集器和軌跡函式將查詢 "done" 條目來評估環境是否應重置。
注意
可以使用 torchrl.collectors.utils.split_trajectories 函式來切片相鄰的軌跡。它依賴於輸入 tensordict 中的 "traj_ids" 條目,或者在 "traj_ids" 缺失時依賴於 "done" 和 "truncated" 鍵的連線。
注意
在某些情況下,標記軌跡的第一步可能很有用。TorchRL 透過 InitTracker 轉換提供了此功能。
我們的環境 教程 提供了更多關於如何從頭開始設計自定義環境的資訊。
|
抽象環境父類。 |
|
類似 gym 的環境就是一個環境。 |
|
用於在多程序環境中儲存和傳遞環境元資料的類。 |
部分步進和部分重置¶
TorchRL 允許環境重置部分而非全部環境,或者在一個環境但非所有環境中執行一個步進。如果批次中只有一個環境,則也允許進行部分重置/步進,其行為如下所述。
批處理環境和鎖定批處理¶
在詳細說明部分重置和部分步進的作用之前,我們必須區分環境自身具有批次大小(主要是狀態化環境)的情況,或者環境只是一個簡單的模組,給定任意大小的輸入,它會對所有元素進行批處理操作(主要是無狀態環境)的情況。
這由 batch_locked 屬性控制:批處理鎖定的環境要求所有輸入 tensordict 具有與環境相同的批次大小。這些環境的典型示例是 GymEnv 及其相關類。相反,批處理未鎖定的環境可以處理任何輸入大小。值得注意的例子有 BraxEnv 或 JumanjiEnv。
在批處理未鎖定的環境中執行部分步進很簡單:只需遮蔽不需要執行的 tensordict 部分,將另一部分傳遞給 step,然後將結果與先前的輸入合併。
批處理環境(ParallelEnv 和 SerialEnv)也可以輕鬆處理部分步進,它們只是將動作傳遞給需要執行的子環境。
在所有其他情況下,TorchRL 假定環境能夠正確處理部分步進。
警告
這意味著自定義環境可能會默默地執行非必需的步進,因為 torchrl 無法控制 _step 方法內部發生的事情!
部分步進¶
部分步進透過臨時鍵 “_step” 進行控制,該鍵指向一個布林掩碼,其大小與持有它的 tensordict 相同。能夠處理此情況的類是:
批處理環境:
ParallelEnv和SerialEnv將動作分派給且僅分派給 “_step” 為 True 的環境;批處理未解鎖的環境;
未批處理的環境(即,沒有批次大小的環境)。在這些環境中,
step()方法將首先查詢 “_step” 條目,如果存在,則相應操作。如果Transform例項將 “_step” 條目傳遞給 tensordict,它也會被TransformedEnv自己的 _step 方法捕獲,該方法將跳過 base_env.step 以及任何進一步的轉換。
在處理部分步進時,策略始終是使用步進輸出,並使用輸入 tensordict 的先前內容(如果存在)或 0 值張量(如果找不到張量)來遮蔽缺失值。這意味著如果輸入 tensordict 不包含所有先前的觀察,那麼對於所有未執行步進的元素,輸出 tensordict 將為 0 值。在批處理環境、資料收集器和軌跡實用程式中,不會出現此問題,因為這些類會正確處理資料傳遞。
當 break_when_all_done 為 True 時,部分步進是 rollout() 的一個基本特性,因為在呼叫 _step 時需要跳過具有 True 完成狀態的環境。
ConditionalSkip 轉換允許您以程式設計方式請求(部分)步進跳過。
部分重置¶
部分重置的工作方式與部分步進幾乎相同,但使用 “_reset” 條目。
部分步進的相同限制也適用於部分重置。
同樣,當 break_when_any_done 為 True 時,部分重置是 rollout() 的一個基本特性,因為需要重置具有 True 完成狀態的環境,但不是其他環境。
有關批處理和向量化環境中部分重置的深入分析,請參閱以下段落。
向量化環境¶
向量化(或更準確地說,並行)環境是強化學習中的一個常見特性,因為執行環境步進可能非常耗費 CPU。一些庫,如 gym3 或 EnvPool,提供了同時執行環境批次的介面。雖然它們通常提供非常有競爭力的計算優勢,但它們不一定能支援 TorchRL 所支援的廣泛的環境庫。因此,TorchRL 提供了自己的通用 ParallelEnv 類來並行執行多個環境。由於此類繼承自 SerialEnv,因此它享有與其他環境完全相同的 API。當然,ParallelEnv 的批次大小將對應於其環境計數。
注意
考慮到庫的許多可選依賴項(例如,Gym、Gymnasium 等),在多程序/分散式設定中,警告可能會變得非常煩人。預設情況下,TorchRL 會在子程序中過濾掉這些警告。如果仍希望看到這些警告,可以透過將 torchrl.filter_warnings_subprocess=False 來顯示它們。
重要的是,您的環境規格應與它傳送和接收的輸入和輸出相匹配,因為 ParallelEnv 將根據這些規格建立緩衝區,以與生成的程序進行通訊。請檢查 check_env_specs() 方法以進行一次健全性檢查。
>>> def make_env():
... return GymEnv("Pendulum-v1", from_pixels=True, g=9.81, device="cuda:0")
>>> check_env_specs(env) # this must pass for ParallelEnv to work
>>> env = ParallelEnv(4, make_env)
>>> print(env.batch_size)
torch.Size([4])
ParallelEnv 允許從其包含的環境中檢索屬性:您可以簡單地呼叫
>>> a, b, c, d = env.g # gets the g-force of the various envs, which we set to 9.81 before
>>> print(a)
9.81
TorchRL 使用私有鍵 "_reset" 來指示環境的哪個元件(子環境或代理)應該被重置。這允許重置部分但非全部元件。
"_reset" 鍵有兩個不同的功能:
在呼叫
_reset()時,"_reset"鍵可能存在也可能不存在於輸入 tensordict 中。TorchRL 的約定是,在給定"done"級別上"_reset"鍵的缺失表示該級別的完全重置(除非在更高級別找到了"_reset"鍵,詳見下文)。如果存在,則期望在"_reset"條目為True的元件(沿鍵和形狀維度)將被重置,並且僅限於這些元件。環境在其
_reset()方法中處理"_reset"鍵的方式是其類特有的。設計一個根據"_reset"輸入進行行為的環境是開發者的責任,因為 TorchRL 無法控制_reset()的內部邏輯。但是,在設計該方法時應牢記以下幾點。在呼叫
_reset()之後,輸出將使用"_reset"條目進行掩碼,並且先前step()的輸出將寫入"_reset"為False的地方。實際上,這意味著如果"_reset"修改了未被其暴露的資料,這些修改將丟失。在此掩碼操作之後,"_reset"條目將從reset()輸出中刪除。
必須指出的是,"_reset" 是一個私有鍵,僅在編寫面向內部的特定環境功能時使用。換句話說,它不應在庫外使用,並且開發人員保留在不事先保證的情況下修改透過 "_reset" 設定進行部分重置的邏輯的權利,只要它們不影響 TorchRL 的內部測試。
最後,在設計重置功能時,應牢記以下假設:
每個
"_reset"都與一個"done"條目(+"terminated"和可能的"truncated")配對。這意味著以下結構是不允許的:TensorDict({"done": done, "nested": {"_reset": reset}}, []),因為"_reset"位於與"done"不同的巢狀級別。一個級別的重置並不排除較低級別上
"_reset"的存在,但它會消除其影響。原因很簡單,根級別的"_reset"對應於all()、any()還是對巢狀"done"條目的自定義呼叫是無法預先知道的,並且明確假設根級別的"_reset"是為了覆蓋巢狀值(例如,請參閱PettingZooWrapper實現,其中每個組都有一個或多個與"done"條目相關聯,該條目在根級別使用any或all邏輯進行聚合,具體取決於任務)。在呼叫
env.reset(tensordict)()時,如果有一個部分"_reset"條目將重置部分而非全部完成的子環境,則輸入資料應包含 __未__ 被重置的子環境的資料。此約束的原因在於env._reset(data)的輸出僅對已重置的條目有意義。對於其他條目,TorchRL 無法提前知道它們是否有意義。例如,可以完美地用 0 填充未重置元件的值,在這種情況下,未重置的資料將無意義,應被丟棄。
下面,我們提供了一些 "_reset" 鍵對重置後返回零的環境的預期效果的示例:
>>> # single reset at the root
>>> data = TensorDict({"val": [1, 1], "_reset": [False, True]}, [])
>>> env.reset(data)
>>> print(data.get("val")) # only the second value is 0
tensor([1, 0])
>>> # nested resets
>>> data = TensorDict({
... ("agent0", "val"): [1, 1], ("agent0", "_reset"): [False, True],
... ("agent1", "val"): [2, 2], ("agent1", "_reset"): [True, False],
... }, [])
>>> env.reset(data)
>>> print(data.get(("agent0", "val"))) # only the second value is 0
tensor([1, 0])
>>> print(data.get(("agent1", "val"))) # only the first value is 0
tensor([0, 2])
>>> # nested resets are overridden by a "_reset" at the root
>>> data = TensorDict({
... "_reset": [True, True],
... ("agent0", "val"): [1, 1], ("agent0", "_reset"): [False, True],
... ("agent1", "val"): [2, 2], ("agent1", "_reset"): [True, False],
... }, [])
>>> env.reset(data)
>>> print(data.get(("agent0", "val"))) # reset at the root overrides nested
tensor([0, 0])
>>> print(data.get(("agent1", "val"))) # reset at the root overrides nested
tensor([0, 0])
>>> tensordict = TensorDict({"_reset": [[True], [False], [True], [True]]}, [4])
>>> env.reset(tensordict) # eliminates the "_reset" entry
TensorDict(
fields={
terminated: Tensor(torch.Size([4, 1]), dtype=torch.bool),
done: Tensor(torch.Size([4, 1]), dtype=torch.bool),
pixels: Tensor(torch.Size([4, 500, 500, 3]), dtype=torch.uint8),
truncated: Tensor(torch.Size([4, 1]), dtype=torch.bool),
batch_size=torch.Size([4]),
device=None,
is_shared=True)
注意
效能說明:啟動 ParallelEnv 可能需要很長時間,因為它需要啟動與程序數相同數量的 Python 例項。由於執行 import torch(和其他匯入)所需的時間,啟動並行環境可能成為瓶頸。這就是為什麼 TorchRL 測試如此緩慢的原因。環境啟動後,應觀察到速度大幅提升。
注意
TorchRL 要求精確的規格:另一個需要考慮的事情是,ParallelEnv(以及資料收集器)將根據環境規格建立資料緩衝區,以在不同程序之間傳遞資訊。這意味著規格錯誤(輸入、觀察或獎勵)將在執行時導致中斷,因為資料無法寫入預先分配的緩衝區。通常,在使用 ParallelEnv 之前,應使用 check_env_specs() 測試函式來測試環境。該函式將在預分配的緩衝區和收集的資料不匹配時引發斷言錯誤。
我們還提供了 SerialEnv 類,它具有完全相同的 API,但以序列方式執行。這主要用於測試目的,當用戶想在不啟動子程序的情況下評估 ParallelEnv 的行為時。
除了提供基於程序的並行性的 ParallelEnv 之外,我們還提供了一種使用 MultiThreadedEnv 建立多執行緒環境的方法。該類底層使用 EnvPool 庫,可以實現更高的效能,但同時限制了靈活性——只能建立 EnvPool 中實現的環境。這涵蓋了許多流行的 RL 環境型別(Atari、Classic Control 等),但不能使用任意 TorchRL 環境,而使用 ParallelEnv 則可以。執行 benchmarks/benchmark_batched_envs.py 以比較不同並行化批處理環境的方法。
|
在同一程序中建立一系列環境。批處理環境允許使用者查詢遠端執行的環境的任意方法/屬性。 |
|
每個程序建立一個環境。 |
|
環境建立者類。 |
非同步環境¶
非同步環境允許並行執行多個環境,這可以顯著加快強化學習中的資料收集過程。
AsyncEnvPool 類及其子類提供了使用不同後端(如執行緒和多程序)管理這些環境的靈活介面。
AsyncEnvPool 類作為非同步環境池的基類,提供了管理多個環境併發執行的通用介面。它支援並行執行的不同後端(如執行緒和多程序),並提供了非同步步進和重置環境的方法。
與 ParallelEnv 相反,AsyncEnvPool 及其子類允許在執行某個任務的同時執行給定的一組子環境,從而允許同時運行復雜的非同步作業。例如,可以在策略根據其他環境的輸出來執行時執行某些環境。
當處理具有高(和/或可變)延遲的環境時,此類及其子類尤其有用。
注意
此類及其子類應與 TransformedEnv 和批處理環境一起巢狀使用,但使用者目前無法在使用這些類時使用基礎環境的非同步功能。應優先在 AsyncEnvPool 內巢狀轉換後的環境。如果這不可行,請提交 issue。
類¶
AsyncEnvPool:非同步環境池的基類。它根據提供的引數確定要使用的後端實現,並管理環境的生命週期。ProcessorAsyncEnvPool:使用多程序並行執行環境的AsyncEnvPool的實現。此類管理一個環境池,每個環境執行在自己的程序中,並提供使用程序間通訊進行非同步步進和重置環境的方法。在例項化AsyncEnvPool時,如果將 “multiprocessing” 作為後端傳遞,它會被自動例項化。ThreadingAsyncEnvPool:使用執行緒並行執行環境的AsyncEnvPool的實現。此類管理一個環境池,每個環境執行在自己的執行緒中,並提供使用執行緒池執行器進行非同步步進和重置環境的方法。在例項化AsyncEnvPool時,如果將 “threading” 作為後端傳遞,它會被自動例項化。
示例¶
>>> from functools import partial
>>> from torchrl.envs import AsyncEnvPool, GymEnv
>>> import torch
>>> # Choose backend
>>> backend = "threading"
>>> env = AsyncEnvPool(
>>> [partial(GymEnv, "Pendulum-v1"), partial(GymEnv, "CartPole-v1")],
>>> stack="lazy",
>>> backend=backend
>>> )
>>> # Execute a synchronous reset
>>> reset = env.reset()
>>> print(reset)
>>> # Execute a synchronous step
>>> s = env.rand_step(reset)
>>> print(s)
>>> # Execute an asynchronous step in env 0
>>> s0 = s[0]
>>> s0["action"] = torch.randn(1).clamp(-1, 1)
>>> s0["env_index"] = 0
>>> env.async_step_send(s0)
>>> # Receive data
>>> s0_result = env.async_step_recv()
>>> print('result', s0_result)
>>> # Close env
>>> env.close()
|
非同步環境池的基類,提供了管理多個環境併發執行的通用介面。 |
|
使用多程序並行執行環境的 AsyncEnvPool 的實現。 |
|
使用執行緒並行執行環境的 AsyncEnvPool 的實現。 |
自定義原生 TorchRL 環境¶
TorchRL 提供了一系列自定義內建環境。
|
遵循 TorchRL API 的國際象棋環境。 |
|
一個無狀態的 Pendulum 環境。 |
|
井字棋實現。 |
|
一個使用雜湊模組來識別唯一觀測值的文字生成環境。 |
多代理環境¶
TorchRL 支援開箱即用的多代理學習。在單代理學習管道中使用的相同類可以無縫地用於多代理上下文,而無需任何修改或專用的多代理基礎設施。
從這個角度來看,環境在多代理學習中起著核心作用。在多代理環境中,許多決策代理在共享的世界中進行操作。代理可以觀察到不同的事物,以不同的方式行動,並獲得不同的獎勵。因此,存在許多正規化來模擬多代理環境(DecPODPs、馬爾可夫博弈)。這些正規化之間的一些主要區別包括:
觀察可以是每個代理的,也可以包含一些共享元件。
獎勵可以是每個代理的或共享的。
完成(以及
"truncated"或"terminated")可以是每個代理的或共享的。
TorchRL 感謝其 tensordict.TensorDict 資料載體,能夠適應所有這些可能的正規化。特別是在多代理環境中,每個代理的鍵將儲存在巢狀的“agents” TensorDict 中。此 TensorDict 將具有額外的代理維度,從而將每個代理不同的資料分組。另一方面,共享鍵將保留在第一層,就像在單代理情況下一樣。
讓我們透過一個例子來更好地理解這一點。在這個例子中,我們將使用 VMAS,一個也基於 PyTorch 的多機器人任務模擬器,它在裝置上執行並行批處理模擬。
我們可以建立一個 VMAS 環境並檢視隨機步進的輸出。
>>> from torchrl.envs.libs.vmas import VmasEnv
>>> env = VmasEnv("balance", num_envs=3, n_agents=5)
>>> td = env.rand_step()
>>> td
TensorDict(
fields={
agents: TensorDict(
fields={
action: Tensor(shape=torch.Size([3, 5, 2]))},
batch_size=torch.Size([3, 5])),
next: TensorDict(
fields={
agents: TensorDict(
fields={
info: TensorDict(
fields={
ground_rew: Tensor(shape=torch.Size([3, 5, 1])),
pos_rew: Tensor(shape=torch.Size([3, 5, 1]))},
batch_size=torch.Size([3, 5])),
observation: Tensor(shape=torch.Size([3, 5, 16])),
reward: Tensor(shape=torch.Size([3, 5, 1]))},
batch_size=torch.Size([3, 5])),
done: Tensor(shape=torch.Size([3, 1]))},
batch_size=torch.Size([3]))},
batch_size=torch.Size([3]))
我們可以觀察到,所有代理共享的鍵,例如 **done**,存在於根 tensordict 中,批次大小為 (num_envs,),這表示模擬環境的數量。
另一方面,代理之間不同的鍵,例如 **action**、**reward**、**observation** 和 **info**,存在於巢狀的“agents” tensordict 中,批次大小為 (num_envs, n_agents),這表示額外的代理維度。
多代理張量規格將遵循與 tensordicts 相同的樣式。與代理相關的值的規格需要巢狀在“agents”條目中。
這是一個在只有完成標誌在代理之間共享的多代理環境中建立規格的示例(如 VMAS):
>>> action_specs = []
>>> observation_specs = []
>>> reward_specs = []
>>> info_specs = []
>>> for i in range(env.n_agents):
... action_specs.append(agent_i_action_spec)
... reward_specs.append(agent_i_reward_spec)
... observation_specs.append(agent_i_observation_spec)
>>> env.action_spec = Composite(
... {
... "agents": Composite(
... {"action": torch.stack(action_specs)}, shape=(env.n_agents,)
... )
... }
...)
>>> env.reward_spec = Composite(
... {
... "agents": Composite(
... {"reward": torch.stack(reward_specs)}, shape=(env.n_agents,)
... )
... }
...)
>>> env.observation_spec = Composite(
... {
... "agents": Composite(
... {"observation": torch.stack(observation_specs)}, shape=(env.n_agents,)
... )
... }
...)
>>> env.done_spec = Categorical(
... n=2,
... shape=torch.Size((1,)),
... dtype=torch.bool,
... )
正如您所見,這非常簡單!每個代理的鍵將具有巢狀的複合規格,而共享鍵將遵循單代理標準。
注意
由於獎勵、完成和動作鍵可能帶有額外的“agent”字首(例如,(“agents”,”action”)),因此 TorchRL 元件其他引數中使用的預設鍵(例如,“action”)將不完全匹配。因此,TorchRL 提供了 env.action_key、env.reward_key 和 env.done_key 屬性,它們將自動指向要使用的正確鍵。請確保將這些屬性傳遞給 TorchRL 中的各種元件,以告知它們正確的鍵(例如,loss.set_keys() 函式)。
注意
TorchRL 會抽象這些巢狀的規格以方便使用。這意味著訪問 env.reward_spec 將始終返回葉子規格,如果訪問的規格是 Composite。因此,如果在上面的示例中,我們在環境建立後執行 env.reward_spec,我們將獲得與 torch.stack(reward_specs)} 相同的輸出。要獲取帶有“agents”鍵的完整複合規格,可以執行 env.output_spec[“full_reward_spec”]。對於動作和完成規格也是如此。請注意,env.reward_spec == env.output_spec[“full_reward_spec”][env.reward_key]。
|
Marl Group Map 型別。 |
|
檢查 MARL 組對映。 |
自動重置環境¶
自動重置環境是指在軌跡收集過程中,當環境達到 "done" 狀態時,不期望呼叫 reset(),因為重置是自動發生的。通常,在這種情況下,與完成和獎勵一起提供的觀察(實際上是執行環境中的動作的結果)是新劇集的第一個觀察,而不是當前劇集的最後一個觀察。
為了處理這些情況,torchrl 提供了一個 AutoResetTransform,它會將呼叫 step 產生的結果觀察複製到下一個 reset,並在軌跡收集過程中(在 rollout() 和 SyncDataCollector 迭代中)跳過 reset 的呼叫。此類還提供了對無效觀察要採用的行為的精細控制,這些行為可以用 “nan” 或任何其他值進行掩碼,或者根本不進行掩碼。
要告知 torchrl 環境是自動重置的,只需在建構函式中提供 auto_reset 引數即可。如果提供了該引數,還可以使用 auto_reset_replace 引數控制是否將劇集最後一個觀察的值替換為佔位符。
>>> from torchrl.envs import GymEnv
>>> from torchrl.envs import set_gym_backend
>>> import torch
>>> torch.manual_seed(0)
>>>
>>> class AutoResettingGymEnv(GymEnv):
... def _step(self, tensordict):
... tensordict = super()._step(tensordict)
... if tensordict["done"].any():
... td_reset = super().reset()
... tensordict.update(td_reset.exclude(*self.done_keys))
... return tensordict
...
... def _reset(self, tensordict=None):
... if tensordict is not None and "_reset" in tensordict:
... return tensordict.copy()
... return super()._reset(tensordict)
>>>
>>> with set_gym_backend("gym"):
... env = AutoResettingGymEnv("CartPole-v1", auto_reset=True, auto_reset_replace=True)
... env.set_seed(0)
... r = env.rollout(30, break_when_any_done=False)
>>> print(r["next", "done"].squeeze())
tensor([False, False, False, False, False, False, False, False, False, False,
False, False, False, True, False, False, False, False, False, False,
False, False, False, False, False, True, False, False, False, False])
>>> print("observation after reset are set as nan", r["next", "observation"])
observation after reset are set as nan tensor([[-4.3633e-02, -1.4877e-01, 1.2849e-02, 2.7584e-01],
[-4.6609e-02, 4.6166e-02, 1.8366e-02, -1.2761e-02],
[-4.5685e-02, 2.4102e-01, 1.8111e-02, -2.9959e-01],
[-4.0865e-02, 4.5644e-02, 1.2119e-02, -1.2542e-03],
[-3.9952e-02, 2.4059e-01, 1.2094e-02, -2.9009e-01],
[-3.5140e-02, 4.3554e-01, 6.2920e-03, -5.7893e-01],
[-2.6429e-02, 6.3057e-01, -5.2867e-03, -8.6963e-01],
[-1.3818e-02, 8.2576e-01, -2.2679e-02, -1.1640e+00],
[ 2.6972e-03, 1.0212e+00, -4.5959e-02, -1.4637e+00],
[ 2.3121e-02, 1.2168e+00, -7.5232e-02, -1.7704e+00],
[ 4.7457e-02, 1.4127e+00, -1.1064e-01, -2.0854e+00],
[ 7.5712e-02, 1.2189e+00, -1.5235e-01, -1.8289e+00],
[ 1.0009e-01, 1.0257e+00, -1.8893e-01, -1.5872e+00],
[ nan, nan, nan, nan],
[-3.9405e-02, -1.7766e-01, -1.0403e-02, 3.0626e-01],
[-4.2959e-02, -3.7263e-01, -4.2775e-03, 5.9564e-01],
[-5.0411e-02, -5.6769e-01, 7.6354e-03, 8.8698e-01],
[-6.1765e-02, -7.6292e-01, 2.5375e-02, 1.1820e+00],
[-7.7023e-02, -9.5836e-01, 4.9016e-02, 1.4826e+00],
[-9.6191e-02, -7.6387e-01, 7.8667e-02, 1.2056e+00],
[-1.1147e-01, -9.5991e-01, 1.0278e-01, 1.5219e+00],
[-1.3067e-01, -7.6617e-01, 1.3322e-01, 1.2629e+00],
[-1.4599e-01, -5.7298e-01, 1.5848e-01, 1.0148e+00],
[-1.5745e-01, -7.6982e-01, 1.7877e-01, 1.3527e+00],
[-1.7285e-01, -9.6668e-01, 2.0583e-01, 1.6956e+00],
[ nan, nan, nan, nan],
[-4.3962e-02, 1.9845e-01, -4.5015e-02, -2.5903e-01],
[-3.9993e-02, 3.9418e-01, -5.0196e-02, -5.6557e-01],
[-3.2109e-02, 5.8997e-01, -6.1507e-02, -8.7363e-01],
[-2.0310e-02, 3.9574e-01, -7.8980e-02, -6.0090e-01]])
動態規格¶
並行執行環境通常是透過建立記憶體緩衝區來實現的,這些緩衝區用於在不同程序之間傳遞資訊。在某些情況下,無法預測環境在軌跡收集過程中是否會有一致的輸入或輸出,因為它們的形狀可能是可變的。我們將這種情況稱為動態規格。
TorchRL 能夠處理動態規格,但批處理環境和收集器需要了解此功能。請注意,實際上,這是自動檢測的。
要指示張量將沿某個維度具有可變大小,可以將所需維度的大小值設定為 -1。由於資料不能連續堆疊,因此需要使用 return_contiguous=False 引數呼叫 env.rollout。以下是一個工作示例:
>>> from torchrl.envs import EnvBase
>>> from torchrl.data import Unbounded, Composite, Bounded, Binary
>>> import torch
>>> from tensordict import TensorDict, TensorDictBase
>>>
>>> class EnvWithDynamicSpec(EnvBase):
... def __init__(self, max_count=5):
... super().__init__(batch_size=())
... self.observation_spec = Composite(
... observation=Unbounded(shape=(3, -1, 2)),
... )
... self.action_spec = Bounded(low=-1, high=1, shape=(2,))
... self.full_done_spec = Composite(
... done=Binary(1, shape=(1,), dtype=torch.bool),
... terminated=Binary(1, shape=(1,), dtype=torch.bool),
... truncated=Binary(1, shape=(1,), dtype=torch.bool),
... )
... self.reward_spec = Unbounded((1,), dtype=torch.float)
... self.count = 0
... self.max_count = max_count
...
... def _reset(self, tensordict=None):
... self.count = 0
... data = TensorDict(
... {
... "observation": torch.full(
... (3, self.count + 1, 2),
... self.count,
... dtype=self.observation_spec["observation"].dtype,
... )
... }
... )
... data.update(self.done_spec.zero())
... return data
...
... def _step(
... self,
... tensordict: TensorDictBase,
... ) -> TensorDictBase:
... self.count += 1
... done = self.count >= self.max_count
... observation = TensorDict(
... {
... "observation": torch.full(
... (3, self.count + 1, 2),
... self.count,
... dtype=self.observation_spec["observation"].dtype,
... )
... }
... )
... done = self.full_done_spec.zero() | done
... reward = self.full_reward_spec.zero()
... return observation.update(done).update(reward)
...
... def _set_seed(self, seed: Optional[int]) -> None:
... self.manual_seed = seed
... return seed
>>> env = EnvWithDynamicSpec()
>>> print(env.rollout(5, return_contiguous=False))
LazyStackedTensorDict(
fields={
action: Tensor(shape=torch.Size([5, 2]), device=cpu, dtype=torch.float32, is_shared=False),
done: Tensor(shape=torch.Size([5, 1]), device=cpu, dtype=torch.bool, is_shared=False),
next: LazyStackedTensorDict(
fields={
done: Tensor(shape=torch.Size([5, 1]), device=cpu, dtype=torch.bool, is_shared=False),
observation: Tensor(shape=torch.Size([5, 3, -1, 2]), device=cpu, dtype=torch.float32, is_shared=False),
reward: Tensor(shape=torch.Size([5, 1]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([5, 1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([5, 1]), device=cpu, dtype=torch.bool, is_shared=False)},
exclusive_fields={
},
batch_size=torch.Size([5]),
device=None,
is_shared=False,
stack_dim=0),
observation: Tensor(shape=torch.Size([5, 3, -1, 2]), device=cpu, dtype=torch.float32, is_shared=False),
terminated: Tensor(shape=torch.Size([5, 1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([5, 1]), device=cpu, dtype=torch.bool, is_shared=False)},
exclusive_fields={
},
batch_size=torch.Size([5]),
device=None,
is_shared=False,
stack_dim=0)
警告
在 ParallelEnv 和資料收集器中缺少記憶體緩衝區可能會嚴重影響這些類的效能。任何此類使用都應與單個程序上的純執行進行仔細基準測試,因為序列化和反序列化大量張量可能非常昂貴。
目前,check_env_specs() 對於沿某些維度形狀可變的動態規格會透過,但對於在一次步進中存在而在其他步進中不存在的鍵,或者維度數量可變的鍵,則不會。
變換 (Transforms)¶
在大多數情況下,環境的原始輸出必須在傳遞給另一個物件(如策略或值運算子)之前進行處理。為此,TorchRL 提供了一組轉換,旨在複製 torch.distributions.Transform 和 torchvision.transforms 的轉換邏輯。我們的環境 教程 提供了更多關於如何設計自定義轉換的資訊。
轉換後的環境是使用 TransformedEnv 原語構建的。複合轉換使用 Compose 類構建。
>>> base_env = GymEnv("Pendulum-v1", from_pixels=True, device="cuda:0")
>>> transform = Compose(ToTensorImage(in_keys=["pixels"]), Resize(64, 64, in_keys=["pixels"]))
>>> env = TransformedEnv(base_env, transform)
轉換通常是 Transform 的子類,儘管任何 Callable[[TensorDictBase], TensorDictBase] 都可以。
預設情況下,轉換後的環境將繼承傳遞給它的 base_env 的裝置。然後,轉換將在該裝置上執行。現在顯而易見,這可以帶來顯著的速度提升,具體取決於要計算的操作型別。
環境包裝器的一個巨大優點是,可以檢查環境直到該包裝器。使用 TorchRL 轉換後的環境也可以實現相同的功能:parent 屬性將返回一個新的 TransformedEnv,其中包含直到感興趣的轉換的所有轉換。重用上面的示例:
>>> resize_parent = env.transform[-1].parent # returns the same as TransformedEnv(base_env, transform[:-1])
轉換後的環境可以與向量化環境一起使用。由於每個轉換都使用 "in_keys"/"out_keys" 關鍵字引數集,因此很容易將轉換圖根植於觀察資料的每個元件(例如,畫素或狀態等)。
正向和反向轉換¶
轉換還具有一個 inv() 方法,該方法在動作透過複合轉換鏈反向應用之前被呼叫。這允許在環境中應用轉換,然後才在環境中採取動作。要包含在此反向轉換中的鍵透過 “in_keys_inv” 關鍵字引數傳遞,而在大多數情況下,out-keys 預設等於這些值。
>>> env.append_transform(DoubleToFloat(in_keys_inv=["action"])) # will map the action from float32 to float64 before calling the base_env.step
以下段落詳細說明了如何考慮 in_ 或 out_ 特徵。
理解轉換鍵¶
在轉換中,in_keys 和 out_keys 定義了基礎環境與外部世界(例如,您的策略)之間的互動。
in_keys 指的是基礎環境的視角(內部 =
TransformedEnv的 base_env)。out_keys 指的是外部世界(外部 = policy、agent 等)。
例如,使用 in_keys=[“obs”] 和 out_keys=[“obs_standardized”],策略將“看到”一個標準化的觀察,而基礎環境輸出一個常規觀察。
類似地,對於反向鍵:
in_keys_inv 指的是基礎環境所見的條目。
out_keys_inv 指的是策略所見或產生的條目。
下圖說明了 RenameTransform 類的這一概念:step 函式的輸入 TensorDict 必須包含 out_keys_inv,因為它們是外部世界的一部分。轉換會更改這些名稱以匹配內部基礎環境的名稱,使用 in_keys_inv。反向過程使用輸出 tensordict 執行,其中 in_keys 被對映到相應的 out_keys。
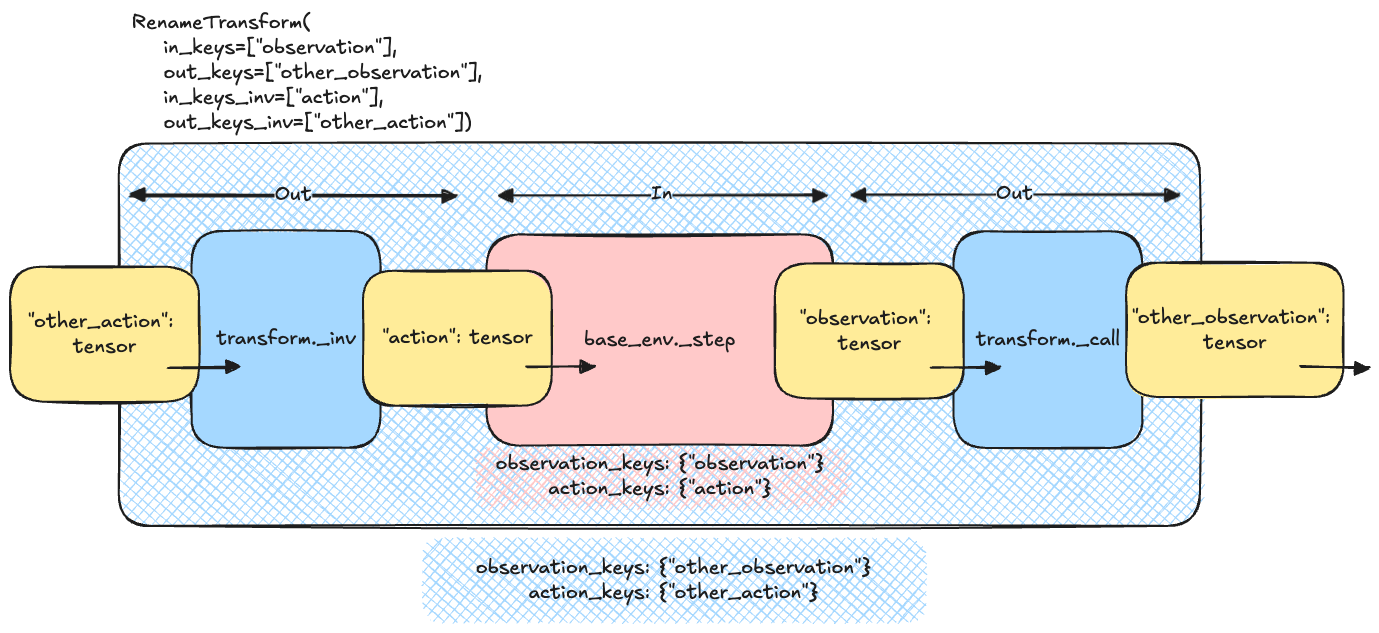
重新命名轉換邏輯¶
注意
在呼叫 inv 時,轉換按相反的順序執行(與正向/步進模式相比)。
轉換張量和規格¶
轉換實際張量(來自策略)時,過程如圖所示:
>>> for t in reversed(self.transform):
... td = t.inv(td)
從最外層轉換到最內層轉換,確保策略暴露的動作值被正確轉換。
對於轉換動作規格,過程應從最內層到最外層(類似於觀察規格)。
>>> def transform_action_spec(self, action_spec):
... for t in self.transform:
... action_spec = t.transform_action_spec(action_spec)
... return action_spec
單個 transform_action_spec 的虛擬碼如下:
>>> def transform_action_spec(self, action_spec):
... return spec_from_random_values(self._apply_transform(action_spec.rand()))
此方法確保“外部”規格是從“內部”規格推斷出來的。請注意,我們特意未呼叫 _inv_apply_transform 而是 _apply_transform!
將規格暴露給外部世界¶
TransformedEnv 將暴露與 out_keys_inv 對應的動作和狀態規格。例如,使用 ActionDiscretizer 時,環境的動作(例如 “action”)是一個浮點值張量,在使用轉換後的環境使用 rand_action() 時不應生成該張量。相反,應該生成 “action_discrete”,並透過轉換獲得其連續對應項。因此,使用者應該看到 “action_discrete” 條目被公開,但不應該看到 “action”。
設計自己的轉換¶
要建立基本的自定義轉換,您需要繼承 Transform 類並實現 _apply_transform() 方法。這是一個向觀察張量加 1 的簡單轉換的示例:
>>> class AddOneToObs(Transform):
... """A transform that adds 1 to the observation tensor."""
...
... def __init__(self):
... super().__init__(in_keys=["observation"], out_keys=["observation"])
...
... def _apply_transform(self, obs: torch.Tensor) -> torch.Tensor:
... return obs + 1
繼承 Transform 的技巧¶
有多種方法可以繼承轉換。需要考慮的事項是:
轉換對於每個被轉換的張量/項是否相同?使用
_apply_transform()和_inv_apply_transform()。轉換是否需要訪問輸入資料到 env.step 以及輸出?重寫
_step()。否則,重寫_call()(或_inv_call())。轉換是否要在回放緩衝區中使用?重寫
forward()、inv()、_apply_transform()或_inv_apply_transform()。在轉換內部,您可以使用
parent(基礎 env + 直到此處的*所有*轉換)或container()(封裝轉換的物件)來訪問(並呼叫)父環境。請記住,如果需要,請編輯規範:頂級:
transform_output_spec()、transform_input_spec()。葉級:transform_observation_spec()、transform_action_spec()、transform_state_spec()、transform_reward_spec()和transform_reward_spec()。
有關實際示例,請參閱上述方法。
您可以透過將轉換傳遞給 TransformedEnv 建構函式來在環境中將其用作轉換。
>>> env = TransformedEnv(GymEnv("Pendulum-v1"), AddOneToObs())
您可以使用 Compose 類將多個轉換組合在一起。
>>> transform = Compose(AddOneToObs(), RewardSum())
>>> env = TransformedEnv(GymEnv("Pendulum-v1"), transform)
反向轉換¶
某些轉換具有可以用來撤消轉換的反向轉換。例如,AddOneToAction 轉換有一個反向轉換,它從動作張量中減去 1。
>>> class AddOneToAction(Transform):
... """A transform that adds 1 to the action tensor."""
... def __init__(self):
... super().__init__(in_keys=[], out_keys=[], in_keys_inv=["action"], out_keys_inv=["action"])
... def _inv_apply_transform(self, action: torch.Tensor) -> torch.Tensor:
... return action + 1
將轉換與回放緩衝區結合使用¶
您可以透過將轉換傳遞給 ReplayBuffer 建構函式來將其與回放緩衝區結合使用。
克隆轉換¶
由於附加到環境的轉換是透過 transform.parent 屬性“註冊”到該環境的,因此在處理轉換時,我們應該記住父級可能會根據對轉換的操作而出現或消失。以下是一些示例:如果我們從 Compose 物件中獲取單個轉換,該轉換將保留其父級。
>>> third_transform = env.transform[2]
>>> assert third_transform.parent is not None
這意味著禁止將此轉換用於另一個環境,因為另一個環境將替換父級,這可能會導致意外行為。幸運的是,Transform 類提供了一個 clone() 方法,該方法將在保留所有註冊緩衝區的身份的同時刪除父級。
>>> TransformedEnv(base_env, third_transform) # raises an Exception as third_transform already has a parent
>>> TransformedEnv(base_env, third_transform.clone()) # works
在單個程序中,或者如果緩衝區放置在共享記憶體中,那麼所有克隆的轉換將保持相同的行為,即使緩衝區被原地更改(例如,CatFrames 轉換就是如此)。在分散式環境中,情況可能並非如此,使用者應注意克隆轉換在此上下文中的預期行為。最後,請注意,從 Compose 轉換中索引多個轉換也可能導致這些轉換失去父級:原因是索引 Compose 轉換會產生另一個不具有父環境的 Compose 轉換。因此,我們必須克隆子轉換才能建立其他組合。
>>> env = TransformedEnv(base_env, Compose(transform1, transform2, transform3))
>>> last_two = env.transform[-2:]
>>> assert isinstance(last_two, Compose)
>>> assert last_two.parent is None
>>> assert last_two[0] is not transform2
>>> assert isinstance(last_two[0], type(transform2)) # and the buffers will match
>>> assert last_two[1] is not transform3
>>> assert isinstance(last_two[1], type(transform3)) # and the buffers will match
|
環境轉換的基類,用於修改或建立 tensordict 中的新資料。 |
|
已轉換的環境。 |
|
用於離散化連續動作空間的轉換。 |
|
自適應動作掩碼器。 |
|
用於自動重置環境的子類。 |
|
用於自動重置環境的轉換。 |
|
用於修改環境批處理大小的轉換。 |
|
將獎勵對映為二進位制值(分別為 0 或 1),如果獎勵為零或非零。 |
|
用於部分燒入資料序列的轉換。 |
|
將連續的觀測幀連線成一個張量。 |
|
將多個鍵連線成一個張量。 |
|
裁剪影像的中心。 |
|
用於裁剪輸入(狀態、動作)或輸出(觀測、獎勵)值的轉換。 |
|
組合一系列轉換。 |
|
一種根據指定條件有條件地在策略之間切換的轉換。 |
|
一種在滿足特定條件時跳過環境中步驟的轉換。 |
|
在指定位置和輸出大小處裁剪輸入影像。 |
|
將一個 dtype 轉換為另一個 dtype,針對選定的鍵。 |
|
將資料從一個裝置移動到另一個裝置。 |
|
將離散動作從高維空間投影到低維空間。 |
|
將一個 dtype 轉換為另一個 dtype,針對選定的鍵。 |
|
使用 lives 方法註冊來自 Gym 環境的生命結束訊號。 |
|
從資料中排除鍵。 |
此轉換將檢查 tensordict 的所有項是否有限,如果不是則引發異常。 |
|
|
展平張量的相鄰維度。 |
|
幀跳過轉換。 |
|
將畫素觀測轉換為灰度。 |
|
向 tensordict 新增雜湊值。 |
|
重置跟蹤器。 |
|
一種用於向獎勵新增 KL[pi_current||pi_0] 校正項的轉換。 |
|
透過加權求和將多目標獎勵訊號轉換為單目標獎勵訊號。 |
|
用於在父環境中執行多個動作的轉換。 |
|
在重置環境時執行一系列隨機動作。 |
|
觀測仿射變換層。 |
|
觀測轉換的抽象類。 |
|
置換轉換。 |
呼叫 tensordict 的 pin_memory 以便在 CUDA 裝置上寫入。 |
|
|
R3M 轉換類。 |
|
用於回放緩衝區和模組的軌跡子取樣器。 |
|
從環境中刪除空的規範和內容。 |
|
用於重新命名輸出 tensordict 中的條目(或透過反向鍵重新命名輸入 tensordict)的轉換。 |
|
調整畫素觀測的大小。 |
|
根據劇集獎勵和折扣因子計算目標獎勵。 |
|
將獎勵裁剪在 clamp_min 和 clamp_max 之間。 |
|
獎勵的仿射變換。 |
|
跟蹤劇集累積獎勵。 |
|
從輸入 tensordict 中選擇鍵。 |
|
用於計算 TensorDict 值符號的轉換。 |
|
在指定位置刪除大小為一的維度。 |
|
堆疊張量和 tensordict。 |
|
從重置開始計數步驟,並在達到一定步數後可選地將截斷狀態設定為 |
|
為代理在環境中設定的目標收益。 |
|
用於在重置時初始化 TensorDict 的 primer。 |
|
在最後 T 個觀測值中,取每個位置的最大值。 |
|
一種用於測量環境中 inv 和 call 操作之間時間間隔的轉換。 |
|
對指定輸入應用分詞操作。 |
|
將類 numpy 影像(W x H x C)轉換為 PyTorch 影像(C x W x H)。 |
|
全域性軌跡計數器轉換。 |
|
對指定的輸入應用一元操作。 |
|
在指定位置插入大小為一的維度。 |
|
VC1 轉換類。 |
|
一種 VIP 轉換,用於根據嵌入相似性計算獎勵。 |
|
VIP 轉換類。 |
|
用於 GymWrapper 子類的轉換,可處理一致的自動重置。 |
|
torchrl 環境的移動平均歸一化層。 |
|
用於在強化學習環境中對向量化觀測和獎勵進行歸一化的類。 |
|
gSDE 噪聲初始化器。 |
具有動作掩碼的環境¶
在某些具有離散動作的環境中,代理可用的動作可能會在執行過程中發生變化。在這種情況下,環境將輸出一個動作掩碼(預設為 "action_mask" 鍵)。此掩碼需要用於過濾掉該步驟中不可用的動作。
如果您使用的是自定義策略,則可以像這樣將此掩碼傳遞給您的機率分佈。
>>> from tensordict.nn import TensorDictModule, ProbabilisticTensorDictModule, TensorDictSequential
>>> import torch.nn as nn
>>> from torchrl.modules import MaskedCategorical
>>> module = TensorDictModule(
>>> nn.Linear(in_feats, out_feats),
>>> in_keys=["observation"],
>>> out_keys=["logits"],
>>> )
>>> dist = ProbabilisticTensorDictModule(
>>> in_keys={"logits": "logits", "mask": "action_mask"},
>>> out_keys=["action"],
>>> distribution_class=MaskedCategorical,
>>> )
>>> actor = TensorDictSequential(module, dist)
如果您想使用預設策略,則需要將環境包裝在 ActionMask 轉換中。此轉換可以處理動作規範中動作掩碼的更新,以便預設策略始終知道最新的可用動作。您可以這樣做:
>>> from tensordict.nn import TensorDictModule, ProbabilisticTensorDictModule, TensorDictSequential
>>> import torch.nn as nn
>>> from torchrl.envs.transforms import TransformedEnv, ActionMask
>>> env = TransformedEnv(
>>> your_base_env
>>> ActionMask(action_key="action", mask_key="action_mask"),
>>> )
注意
如果您使用的是並行環境,則必須將轉換新增到並行環境本身,而不是新增到其子環境中。
記錄器¶
在環境滾動執行過程中記錄資料對於密切關注演算法效能以及在訓練後報告結果至關重要。
TorchRL 提供了幾種與環境輸出互動的工具:最重要的是,可以將 callback 可呼叫物件傳遞給 rollout() 方法。此函式將在滾動每次迭代時被呼叫(如果必須跳過某些迭代,則應新增一個內部變數來跟蹤 callback 中的呼叫計數)。
要將收集的 tensordict 儲存到磁碟,可以使用 TensorDictRecorder。
錄製影片¶
幾個後端提供了從環境中錄製渲染影像的可能性。如果畫素已經是環境輸出的一部分(例如,Atari 或其他遊戲模擬器),則可以將 VideoRecorder 附加到環境中。此環境轉換的輸入是一個能夠錄製影片的記錄器(例如 CSVLogger、WandbLogger 或 TensorBoardLogger)以及一個指示影片應儲存位置的標籤。例如,要將 mp4 影片儲存到磁碟,可以使用帶有 video_format=”mp4” 引數的 CSVLogger。
VideoRecorder 轉換可以處理批處理影像,並自動檢測 numpy 或 PyTorch 格式的影像(WHC 或 CWH)。
>>> logger = CSVLogger("dummy-exp", video_format="mp4")
>>> env = GymEnv("ALE/Pong-v5")
>>> env = env.append_transform(VideoRecorder(logger, tag="rendered", in_keys=["pixels"]))
>>> env.rollout(10)
>>> env.transform.dump() # Save the video and clear cache
請注意,轉換的快取將繼續增長,直到呼叫 dump。使用者有責任呼叫 dump 來避免 OOM 問題。
在某些情況下,建立可以收集影像的測試環境可能很麻煩或成本高昂,或者根本不可能(有些庫每個工作區只允許一個環境例項)。在這種情況下,假設環境中存在 render 方法,則可以使用 PixelRenderTransform 在父環境中呼叫 render 並將影像儲存在滾動資料流中。此類同樣適用於單環境和批處理環境。
>>> from torchrl.envs import GymEnv, check_env_specs, ParallelEnv, EnvCreator
>>> from torchrl.record.loggers import CSVLogger
>>> from torchrl.record.recorder import PixelRenderTransform, VideoRecorder
>>>
>>> def make_env():
>>> env = GymEnv("CartPole-v1", render_mode="rgb_array")
>>> # Uncomment this line to execute per-env
>>> # env = env.append_transform(PixelRenderTransform())
>>> return env
>>>
>>> if __name__ == "__main__":
... logger = CSVLogger("dummy", video_format="mp4")
...
... env = ParallelEnv(16, EnvCreator(make_env))
... env.start()
... # Comment this line to execute per-env
... env = env.append_transform(PixelRenderTransform())
...
... env = env.append_transform(VideoRecorder(logger=logger, tag="pixels_record"))
... env.rollout(3)
...
... check_env_specs(env)
...
... r = env.rollout(30)
... env.transform.dump()
... env.close()
記錄器是轉換,用於在資料傳入時註冊資料,以供記錄。
|
TensorDict 錄製器。 |
|
影片錄製器轉換。 |
|
一個呼叫父環境的 render 方法並將畫素觀察註冊到 tensordict 中的轉換。 |
輔助工具¶
|
資料收集器的隨機策略。 |
|
使用簡短的 rollout 來測試環境規範。 |
返回當前的取樣型別。 |
|
返回所有支援的庫。 |
|
|
從 tensordict 建立 Composite 例項,假設所有值都是無界的。 |
的別名 |
|
|
建立一個反映輸入 tensordict 時間步長的新 tensordict。 |
|
讀取 tensordict 中的 done / terminated / truncated 鍵,並寫入一個新張量,其中兩個訊號的值都被聚合。 |
特定領域¶
|
基於模型的 RL sota 實現的基礎環境。 |
|
Dreamer 模擬環境。 |
用於在 Dreamer 中記錄解碼觀測值的轉換。 |
庫¶
TorchRL 的使命是讓控制和決策演算法的訓練儘可能簡單,無論使用何種模擬器(如果有)。提供了適用於 DMControl、Habitat、Jumanji 以及 Gym 的多種包裝器。
最後一個庫在 RL 社群中具有特殊地位,因為它是最常用的編碼模擬器框架。其成功的 API 具有基礎性,並啟發了許多其他框架,包括 TorchRL。然而,Gym 經歷了幾次設計更改,作為外部採用庫有時很難適應這些更改:使用者通常有他們“偏好”的版本。此外,gym 現在由另一個名為“gymnasium”的組維護,這不利於程式碼相容性。實際上,我們必須考慮到使用者可能在同一個虛擬環境中安裝了 gym *和* gymnasium 的版本,並且我們必須允許兩者同時工作。幸運的是,TorchRL 為此問題提供了一個解決方案:一個特殊的裝飾器 set_gym_backend 可以控制在相關函式中使用哪個庫。
>>> from torchrl.envs.libs.gym import GymEnv, set_gym_backend, gym_backend
>>> import gymnasium, gym
>>> with set_gym_backend(gymnasium):
... print(gym_backend())
... env1 = GymEnv("Pendulum-v1")
<module 'gymnasium' from '/path/to/venv/python3.10/site-packages/gymnasium/__init__.py'>
>>> with set_gym_backend(gym):
... print(gym_backend())
... env2 = GymEnv("Pendulum-v1")
<module 'gym' from '/path/to/venv/python3.10/site-packages/gym/__init__.py'>
>>> print(env1._env.env.env)
<gymnasium.envs.classic_control.pendulum.PendulumEnv at 0x15147e190>
>>> print(env2._env.env.env)
<gym.envs.classic_control.pendulum.PendulumEnv at 0x1629916a0>
我們可以看到,這兩個庫都修改了 gym_backend() 返回的值,該值可用於指示當前計算需要使用哪個庫。set_gym_backend 也是一個裝飾器:我們可以使用它來告訴特定函式在其執行期間需要使用哪個 gym 後端。torchrl.envs.libs.gym.gym_backend() 函式允許您收集當前的 gym 後端或其任何模組。
>>> import mo_gymnasium
>>> with set_gym_backend("gym"):
... wrappers = gym_backend('wrappers')
... print(wrappers)
<module 'gym.wrappers' from '/path/to/venv/python3.10/site-packages/gym/wrappers/__init__.py'>
>>> with set_gym_backend("gymnasium"):
... wrappers = gym_backend('wrappers')
... print(wrappers)
<module 'gymnasium.wrappers' from '/path/to/venv/python3.10/site-packages/gymnasium/wrappers/__init__.py'>
另一個在 gym 和其他外部依賴項中很方便的工具是 torchrl._utils.implement_for 類。使用 @implement_for 裝飾一個函式將告訴 torchrl,根據指示的版本,預期會有特定的行為。這使我們能夠輕鬆支援多個 gym 版本,而無需使用者付出任何努力。例如,考慮到我們的虛擬環境安裝了 v0.26.2 版本,以下函式在被查詢時將返回 1。
>>> from torchrl._utils import implement_for
>>> @implement_for("gym", None, "0.26.0")
... def fun():
... return 0
>>> @implement_for("gym", "0.26.0", None)
... def fun():
... return 1
>>> fun()
1
|
使用環境名稱構建的 Google Brax 環境包裝器。 |
|
Google Brax 環境包裝器。 |
|
DeepMind Control 實驗室環境封裝器。 |
|
DeepMind Control 實驗室環境封裝器。 |
|
直接透過環境 ID 構建的 OpenAI Gym 環境包裝器。 |
|
OpenAI Gym 環境包裝器。 |
|
Habitat 環境的包裝器。 |
|
IsaacGym 環境的 TorchRL Env 介面。 |
|
IsaacGymEnvs 環境的包裝器。 |
|
IsaacLab 環境的包裝器。 |
|
使用環境名稱構建的 Jumanji 環境包裝器。 |
|
Jumanji 的環境包裝器。 |
|
Meltingpot 環境包裝器。 |
|
Meltingpot 環境包裝器。 |
|
FARAMA MO-Gymnasium 環境包裝器。 |
|
FARAMA MO-Gymnasium 環境包裝器。 |
|
基於 EnvPool 的環境的多執行緒執行。 |
|
用於基於 envpool 的多執行緒環境的包裝器。 |
|
用於在 the bandit contexts 中使用的 OpenML 資料的環境介面。 |
|
Google DeepMind OpenSpiel 環境包裝器。 |
|
使用遊戲字串構建的 Google DeepMind OpenSpiel 環境包裝器。 |
|
PettingZoo 環境。 |
|
PettingZoo 環境包裝器。 |
|
RoboHive gym 環境的包裝器。 |
|
SMACv2 (StarCraft Multi-Agent Challenge v2) 環境包裝器。 |
|
SMACv2 (StarCraft Multi-Agent Challenge v2) 環境包裝器。 |
|
Unity ML-Agents 環境包裝器。 |
|
Unity ML-Agents 環境包裝器。 |
|
Vmas 環境包裝器。 |
|
Vmas 環境包裝器。 |
|
返回 gym 後端或其子模組。 |
|
將 gym 後端設定為特定值。 |
|
用於註冊特定規範型別的轉換函式的裝飾器。 |
