


注意
轉到末尾 下載完整的示例程式碼。
介紹 || 張量 || 自動微分 || 構建模型 || TensorBoard 支援 || 訓練模型 || 模型理解
使用 PyTorch 進行訓練#
創建於:2021 年 11 月 30 日 | 最後更新於:2023 年 5 月 31 日 | 最後驗證於:2024 年 11 月 05 日
請觀看下面的影片或在 youtube 上觀看。
簡介#
在之前的影片中,我們已經討論並演示了
使用 torch.nn 模組的神經網路層和函式構建模型
自動梯度計算的機制,這是基於梯度的模型訓練的核心
使用 TensorBoard 視覺化訓練進度和其他活動
在本影片中,我們將為您增加一些新工具
我們將熟悉 `Dataset` 和 `DataLoader` 抽象,以及它們如何在訓練迴圈中簡化將資料饋送到模型的過程
我們將討論特定的損失函式以及何時使用它們
我們將介紹 PyTorch 最佳化器,它實現了根據損失函式的結果調整模型權重的演算法
最後,我們將把所有這些結合起來,看看一個完整的 PyTorch 訓練迴圈的實際執行。
資料集和 DataLoader#
`Dataset` 和 `DataLoader` 類封裝了從儲存中提取資料並在批次中將其暴露給訓練迴圈的過程。
`Dataset` 負責訪問和處理單個數據實例。
`DataLoader` 從 `Dataset` 中提取資料例項(自動或使用您定義的取樣器),將它們收整合批次,然後返回供您的訓練迴圈使用。`DataLoader` 可以與任何型別的資料集一起使用,無論它們包含什麼型別的資料。
在本教程中,我們將使用 TorchVision 提供的 Fashion-MNIST 資料集。我們使用 `torchvision.transforms.Normalize()` 來零均值化並規範化影像塊內容的分佈,並下載訓練和驗證資料分割。
import torch
import torchvision
import torchvision.transforms as transforms
# PyTorch TensorBoard support
from torch.utils.tensorboard import SummaryWriter
from datetime import datetime
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
# Create datasets for training & validation, download if necessary
training_set = torchvision.datasets.FashionMNIST('./data', train=True, transform=transform, download=True)
validation_set = torchvision.datasets.FashionMNIST('./data', train=False, transform=transform, download=True)
# Create data loaders for our datasets; shuffle for training, not for validation
training_loader = torch.utils.data.DataLoader(training_set, batch_size=4, shuffle=True)
validation_loader = torch.utils.data.DataLoader(validation_set, batch_size=4, shuffle=False)
# Class labels
classes = ('T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle Boot')
# Report split sizes
print('Training set has {} instances'.format(len(training_set)))
print('Validation set has {} instances'.format(len(validation_set)))
0%| | 0.00/26.4M [00:00<?, ?B/s]
0%| | 65.5k/26.4M [00:00<01:12, 362kB/s]
1%| | 197k/26.4M [00:00<00:45, 574kB/s]
3%|▎ | 754k/26.4M [00:00<00:14, 1.71MB/s]
11%|█ | 2.95M/26.4M [00:00<00:04, 5.81MB/s]
30%|██▉ | 7.83M/26.4M [00:00<00:01, 13.4MB/s]
51%|█████ | 13.5M/26.4M [00:01<00:00, 19.4MB/s]
72%|███████▏ | 19.0M/26.4M [00:01<00:00, 23.0MB/s]
89%|████████▉ | 23.6M/26.4M [00:01<00:00, 27.7MB/s]
100%|██████████| 26.4M/26.4M [00:01<00:00, 18.0MB/s]
0%| | 0.00/29.5k [00:00<?, ?B/s]
100%|██████████| 29.5k/29.5k [00:00<00:00, 325kB/s]
0%| | 0.00/4.42M [00:00<?, ?B/s]
1%|▏ | 65.5k/4.42M [00:00<00:12, 356kB/s]
5%|▌ | 229k/4.42M [00:00<00:06, 672kB/s]
20%|██ | 885k/4.42M [00:00<00:01, 1.99MB/s]
62%|██████▏ | 2.72M/4.42M [00:00<00:00, 5.10MB/s]
100%|██████████| 4.42M/4.42M [00:00<00:00, 5.95MB/s]
0%| | 0.00/5.15k [00:00<?, ?B/s]
100%|██████████| 5.15k/5.15k [00:00<00:00, 51.7MB/s]
Training set has 60000 instances
Validation set has 10000 instances
一如既往,讓我們將資料視覺化作為一次健全性檢查
import matplotlib.pyplot as plt
import numpy as np
# Helper function for inline image display
def matplotlib_imshow(img, one_channel=False):
if one_channel:
img = img.mean(dim=0)
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
if one_channel:
plt.imshow(npimg, cmap="Greys")
else:
plt.imshow(np.transpose(npimg, (1, 2, 0)))
dataiter = iter(training_loader)
images, labels = next(dataiter)
# Create a grid from the images and show them
img_grid = torchvision.utils.make_grid(images)
matplotlib_imshow(img_grid, one_channel=True)
print(' '.join(classes[labels[j]] for j in range(4)))
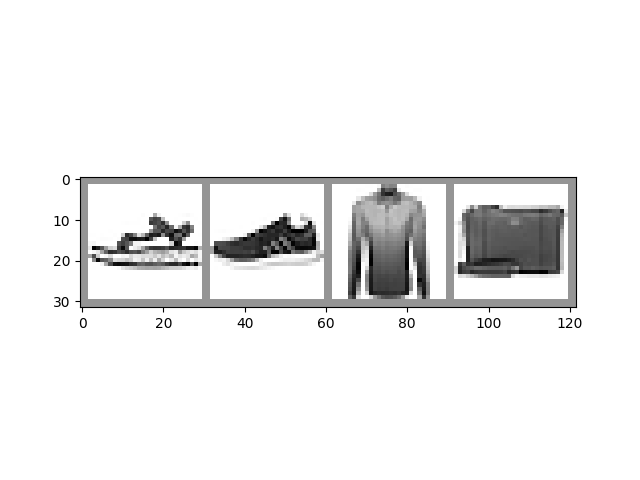
Sandal Sneaker Shirt Bag
模型#
本示例中使用的模型是 LeNet-5 的一個變體 — 如果您看過本系列之前的影片,應該會很熟悉。
import torch.nn as nn
import torch.nn.functional as F
# PyTorch models inherit from torch.nn.Module
class GarmentClassifier(nn.Module):
def __init__(self):
super(GarmentClassifier, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 4 * 4)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
model = GarmentClassifier()
損失函式#
在本示例中,我們將使用交叉熵損失。為演示起見,我們將建立假輸出和標籤值的批次,將它們透過損失函式執行,並檢查結果。
loss_fn = torch.nn.CrossEntropyLoss()
# NB: Loss functions expect data in batches, so we're creating batches of 4
# Represents the model's confidence in each of the 10 classes for a given input
dummy_outputs = torch.rand(4, 10)
# Represents the correct class among the 10 being tested
dummy_labels = torch.tensor([1, 5, 3, 7])
print(dummy_outputs)
print(dummy_labels)
loss = loss_fn(dummy_outputs, dummy_labels)
print('Total loss for this batch: {}'.format(loss.item()))
tensor([[0.5981, 0.7205, 0.4472, 0.4691, 0.1565, 0.5347, 0.4308, 0.1182, 0.9646,
0.4539],
[0.6230, 0.4794, 0.2207, 0.2924, 0.7148, 0.8645, 0.5875, 0.5251, 0.6756,
0.0916],
[0.0501, 0.7904, 0.7441, 0.5225, 0.3061, 0.6760, 0.3924, 0.6372, 0.5151,
0.8732],
[0.2018, 0.5311, 0.8389, 0.1922, 0.0745, 0.7502, 0.9822, 0.4657, 0.7697,
0.1901]])
tensor([1, 5, 3, 7])
Total loss for this batch: 2.2027742862701416
最佳化器#
在本示例中,我們將使用簡單的 隨機梯度下降 和動量。
嘗試對這種最佳化方案進行一些修改可能會有所啟發
學習率決定了最佳化器所採取的步長大小。不同的學習率對您的訓練結果有什麼影響,包括準確率和收斂時間?
動量在多個步驟中將最佳化器推向最強的梯度方向。改變這個值會對您的結果產生什麼影響?
嘗試一些不同的最佳化演算法,例如平均 SGD、Adagrad 或 Adam。您的結果有何不同?
# Optimizers specified in the torch.optim package
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
訓練迴圈#
下面是一個執行一個訓練 epoch 的函式。它列舉 DataLoader 中的資料,並在每次迴圈迭代中執行以下操作:
從 DataLoader 獲取一個訓練資料批次
將最佳化器的梯度清零
執行推理 — 即,從模型獲取輸入批次的預測
計算該組預測與資料集上的標籤之間的損失
計算學習權重的反向梯度
告訴最佳化器執行一個學習步驟 — 即,根據此批次的梯度,按照我們選擇的最佳化演算法調整模型的學習權重
它每 1000 個批次報告一次損失。
最後,它報告最後一個 1000 個批次的平均每批次損失,以便與驗證執行進行比較
def train_one_epoch(epoch_index, tb_writer):
running_loss = 0.
last_loss = 0.
# Here, we use enumerate(training_loader) instead of
# iter(training_loader) so that we can track the batch
# index and do some intra-epoch reporting
for i, data in enumerate(training_loader):
# Every data instance is an input + label pair
inputs, labels = data
# Zero your gradients for every batch!
optimizer.zero_grad()
# Make predictions for this batch
outputs = model(inputs)
# Compute the loss and its gradients
loss = loss_fn(outputs, labels)
loss.backward()
# Adjust learning weights
optimizer.step()
# Gather data and report
running_loss += loss.item()
if i % 1000 == 999:
last_loss = running_loss / 1000 # loss per batch
print(' batch {} loss: {}'.format(i + 1, last_loss))
tb_x = epoch_index * len(training_loader) + i + 1
tb_writer.add_scalar('Loss/train', last_loss, tb_x)
running_loss = 0.
return last_loss
每個 Epoch 的活動#
我們每個 epoch 都需要做幾件事情:
進行驗證,檢查我們在未用於訓練的資料集上的相對損失,並報告此結果
儲存模型的副本
在這裡,我們將在 TensorBoard 中進行報告。這需要您轉到命令列啟動 TensorBoard,然後在另一個瀏覽器標籤頁中開啟它。
# Initializing in a separate cell so we can easily add more epochs to the same run
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
writer = SummaryWriter('runs/fashion_trainer_{}'.format(timestamp))
epoch_number = 0
EPOCHS = 5
best_vloss = 1_000_000.
for epoch in range(EPOCHS):
print('EPOCH {}:'.format(epoch_number + 1))
# Make sure gradient tracking is on, and do a pass over the data
model.train(True)
avg_loss = train_one_epoch(epoch_number, writer)
running_vloss = 0.0
# Set the model to evaluation mode, disabling dropout and using population
# statistics for batch normalization.
model.eval()
# Disable gradient computation and reduce memory consumption.
with torch.no_grad():
for i, vdata in enumerate(validation_loader):
vinputs, vlabels = vdata
voutputs = model(vinputs)
vloss = loss_fn(voutputs, vlabels)
running_vloss += vloss
avg_vloss = running_vloss / (i + 1)
print('LOSS train {} valid {}'.format(avg_loss, avg_vloss))
# Log the running loss averaged per batch
# for both training and validation
writer.add_scalars('Training vs. Validation Loss',
{ 'Training' : avg_loss, 'Validation' : avg_vloss },
epoch_number + 1)
writer.flush()
# Track best performance, and save the model's state
if avg_vloss < best_vloss:
best_vloss = avg_vloss
model_path = 'model_{}_{}'.format(timestamp, epoch_number)
torch.save(model.state_dict(), model_path)
epoch_number += 1
EPOCH 1:
batch 1000 loss: 1.666409859918058
batch 2000 loss: 0.8216810051053762
batch 3000 loss: 0.693145078105852
batch 4000 loss: 0.6443965511168354
batch 5000 loss: 0.6123742864592933
batch 6000 loss: 0.5695766103928909
batch 7000 loss: 0.5409413252712693
batch 8000 loss: 0.5383153433622793
batch 9000 loss: 0.48026449825975576
batch 10000 loss: 0.4591459574009059
batch 11000 loss: 0.45217856835146086
batch 12000 loss: 0.431060717097309
batch 13000 loss: 0.41652981538244055
batch 14000 loss: 0.435001613863511
batch 15000 loss: 0.4117226452493924
LOSS train 0.4117226452493924 valid 0.42531269788742065
EPOCH 2:
batch 1000 loss: 0.3943638932242757
batch 2000 loss: 0.39510620032442967
batch 3000 loss: 0.40187308340048183
batch 4000 loss: 0.41561483964993384
batch 5000 loss: 0.37135440780574575
batch 6000 loss: 0.3847427979120985
batch 7000 loss: 0.3660853395376471
batch 8000 loss: 0.3599262051352125
batch 9000 loss: 0.36613601676898544
batch 10000 loss: 0.34619443843280895
batch 11000 loss: 0.3421523532573119
batch 12000 loss: 0.37944928950941537
batch 13000 loss: 0.3445565646337418
batch 14000 loss: 0.3472710616480363
batch 15000 loss: 0.3482665803800919
LOSS train 0.3482665803800919 valid 0.37191668152809143
EPOCH 3:
batch 1000 loss: 0.35298623689083614
batch 2000 loss: 0.31526475692175154
batch 3000 loss: 0.354445223361603
batch 4000 loss: 0.31954076824391087
batch 5000 loss: 0.30167409399730966
batch 6000 loss: 0.32178128572105563
batch 7000 loss: 0.31245879809299365
batch 8000 loss: 0.3102076395740296
batch 9000 loss: 0.3193566365780716
batch 10000 loss: 0.3245317395089805
batch 11000 loss: 0.32724233834208283
batch 12000 loss: 0.3273154704665576
batch 13000 loss: 0.3198279506397084
batch 14000 loss: 0.3135476417306054
batch 15000 loss: 0.31637832522210374
LOSS train 0.31637832522210374 valid 0.3359675407409668
EPOCH 4:
batch 1000 loss: 0.27941275065656734
batch 2000 loss: 0.2823940862530035
batch 3000 loss: 0.2894134281675447
batch 4000 loss: 0.3015546747631597
batch 5000 loss: 0.28293730535544453
batch 6000 loss: 0.2941953631842043
batch 7000 loss: 0.3244606865464448
batch 8000 loss: 0.2946359610656218
batch 9000 loss: 0.3051677185113658
batch 10000 loss: 0.2765467494608965
batch 11000 loss: 0.31629972430641645
batch 12000 loss: 0.3217379439852521
batch 13000 loss: 0.2986907337167504
batch 14000 loss: 0.2571812377775459
batch 15000 loss: 0.2835259589429043
LOSS train 0.2835259589429043 valid 0.33261457085609436
EPOCH 5:
batch 1000 loss: 0.27721858343805705
batch 2000 loss: 0.2762320360558242
batch 3000 loss: 0.2741196601182746
batch 4000 loss: 0.27815906952939257
batch 5000 loss: 0.2765891040311908
batch 6000 loss: 0.28914274197602935
batch 7000 loss: 0.27360277335835415
batch 8000 loss: 0.2811103402964691
batch 9000 loss: 0.2858065232049412
batch 10000 loss: 0.25068630761879285
batch 11000 loss: 0.2620843322443907
batch 12000 loss: 0.29563811091540265
batch 13000 loss: 0.2757980781155493
batch 14000 loss: 0.27335850994923383
batch 15000 loss: 0.2731545760410836
LOSS train 0.2731545760410836 valid 0.3064103424549103
載入儲存的模型版本
saved_model = GarmentClassifier()
saved_model.load_state_dict(torch.load(PATH))
載入模型後,它就可以滿足您的任何需求 — 進一步的訓練、推理或分析。
請注意,如果您的模型有影響模型結構的建構函式引數,您需要提供它們,並以與儲存時完全相同的方式配置模型。
其他資源#
在 pytorch.org 上,有關 資料實用程式(包括 Dataset 和 DataLoader)的文件
關於 GPU 訓練 固定記憶體使用 的說明
TorchVision、TorchText 和 TorchAudio 中可用資料集的文件 (TorchAudio)
PyTorch 中可用的 損失函式 的文件
包含最佳化器及相關工具(如學習率排程)的 torch.optim 包 的文件
關於 儲存和載入模型 的詳細教程
pytorch.org 的 教程 部分包含各種訓練任務的教程,包括不同領域的分類、生成對抗網路、強化學習等
指令碼總執行時間: (3 分鐘 3.170 秒)
