


注意
跳轉到末尾 下載完整示例程式碼。
PyTorch Profiler With TensorBoard#
建立日期:2021年4月20日 | 最後更新:2024年10月31日 | 最後驗證:2024年11月05日
本教程演示如何使用 TensorBoard 外掛與 PyTorch Profiler 結合,檢測模型的效能瓶頸。
警告
PyTorch profiler 與 TensorBoard 的整合現已棄用。請改用 Perfetto 或 Chrome trace 來檢視 trace.json 檔案。在 生成 trace 後,只需將 trace.json 檔案拖入 Perfetto UI 或 chrome://tracing 即可視覺化您的 profile。
簡介#
PyTorch 1.8 包含了一個更新的 profiler API,能夠記錄 CPU 端的操作以及 GPU 端的 CUDA kernel 啟動。Profiler 可以在 TensorBoard 外掛中視覺化這些資訊,並提供效能瓶頸的分析。
在本教程中,我們將使用一個簡單的 Resnet 模型來演示如何使用 TensorBoard 外掛分析模型效能。
設定#
使用以下命令安裝 torch 和 torchvision
pip install torch torchvision
步驟#
準備資料和模型
使用 profiler 記錄執行事件
執行 profiler
使用 TensorBoard 檢視結果並分析模型效能
在 profiler 的幫助下提升效能
使用其他高階功能分析效能
額外實踐:在 AMD GPU 上進行 PyTorch profiling
1. 準備資料和模型#
首先,匯入所有必需的庫
import torch
import torch.nn
import torch.optim
import torch.profiler
import torch.utils.data
import torchvision.datasets
import torchvision.models
import torchvision.transforms as T
然後準備輸入資料。本教程使用 CIFAR10 資料集。將其轉換為所需格式,並使用 DataLoader 載入每個批次。
transform = T.Compose(
[T.Resize(224),
T.ToTensor(),
T.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_set = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=32, shuffle=True)
接下來,建立 Resnet 模型、損失函式和最佳化器物件。要在 GPU 上執行,請將模型和損失移至 GPU 裝置。
device = torch.device("cuda:0")
model = torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device)
criterion = torch.nn.CrossEntropyLoss().cuda(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
model.train()
定義每個輸入資料批次的訓練步驟。
def train(data):
inputs, labels = data[0].to(device=device), data[1].to(device=device)
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
2. 使用 profiler 記錄執行事件#
Profiler 透過上下文管理器啟用,並接受幾個引數,其中一些最有用的引數是
schedule- 一個可呼叫物件,它以步驟(整數)作為單個引數,並在每個步驟返回要執行的 profiler 操作。在此示例中,使用
wait=1, warmup=1, active=3, repeat=1,profiler 將跳過第一個步驟/迭代,在第二個步驟開始預熱,記錄接下來的三個迭代,之後 trace 將可用,並呼叫 on_trace_ready(如果已設定)。總共,該迴圈重複一次。每次迴圈在 TensorBoard 外掛中稱為一個“span”。在
wait步驟期間,profiler 被停用。在warmup步驟期間,profiler 開始跟蹤,但結果將被丟棄。這是為了減少 profiling 開銷。Profiling 開始時的開銷很高,容易導致 profiling 結果失真。在active步驟期間,profiler 工作並記錄事件。on_trace_ready- 每個週期結束時呼叫的可呼叫物件;在此示例中,我們使用torch.profiler.tensorboard_trace_handler為 TensorBoard 生成結果檔案。Profiling 結束後,結果檔案將儲存在./log/resnet18目錄中。將此目錄指定為logdir引數,可以在 TensorBoard 中分析 profile。record_shapes- 是否記錄運算元輸入的形狀。profile_memory- 跟蹤張量記憶體的分配/釋放。注意,對於低於 1.10 版本的舊版 PyTorch,如果您遇到長時間的 profiling 時間,請停用此選項或升級到新版本。with_stack- 記錄運算元的源資訊(檔名和行號)。如果在 VS Code 中啟動 TensorBoard(參考),單擊堆疊幀將導航到特定程式碼行。
with torch.profiler.profile(
schedule=torch.profiler.schedule(wait=1, warmup=1, active=3, repeat=1),
on_trace_ready=torch.profiler.tensorboard_trace_handler('./log/resnet18'),
record_shapes=True,
profile_memory=True,
with_stack=True
) as prof:
for step, batch_data in enumerate(train_loader):
prof.step() # Need to call this at each step to notify profiler of steps' boundary.
if step >= 1 + 1 + 3:
break
train(batch_data)
或者,也支援以下非上下文管理器 start/stop 方法。
prof = torch.profiler.profile(
schedule=torch.profiler.schedule(wait=1, warmup=1, active=3, repeat=1),
on_trace_ready=torch.profiler.tensorboard_trace_handler('./log/resnet18'),
record_shapes=True,
with_stack=True)
prof.start()
for step, batch_data in enumerate(train_loader):
prof.step()
if step >= 1 + 1 + 3:
break
train(batch_data)
prof.stop()
3. 執行 profiler#
執行上述程式碼。Profiling 結果將儲存在 ./log/resnet18 目錄下。
4. 使用 TensorBoard 檢視結果並分析模型效能#
注意
TensorBoard 外掛支援已棄用,因此其中一些功能可能無法按預期工作。請檢視替代方案 HTA。
安裝 PyTorch Profiler TensorBoard 外掛。
pip install torch_tb_profiler
啟動 TensorBoard。
tensorboard --logdir=./log
在 Google Chrome 瀏覽器或 Microsoft Edge 瀏覽器中開啟 TensorBoard profile URL(Safari 不支援)。
http://localhost:6006/#pytorch_profiler
您將看到如下所示的 Profiler 外掛頁面。
概述
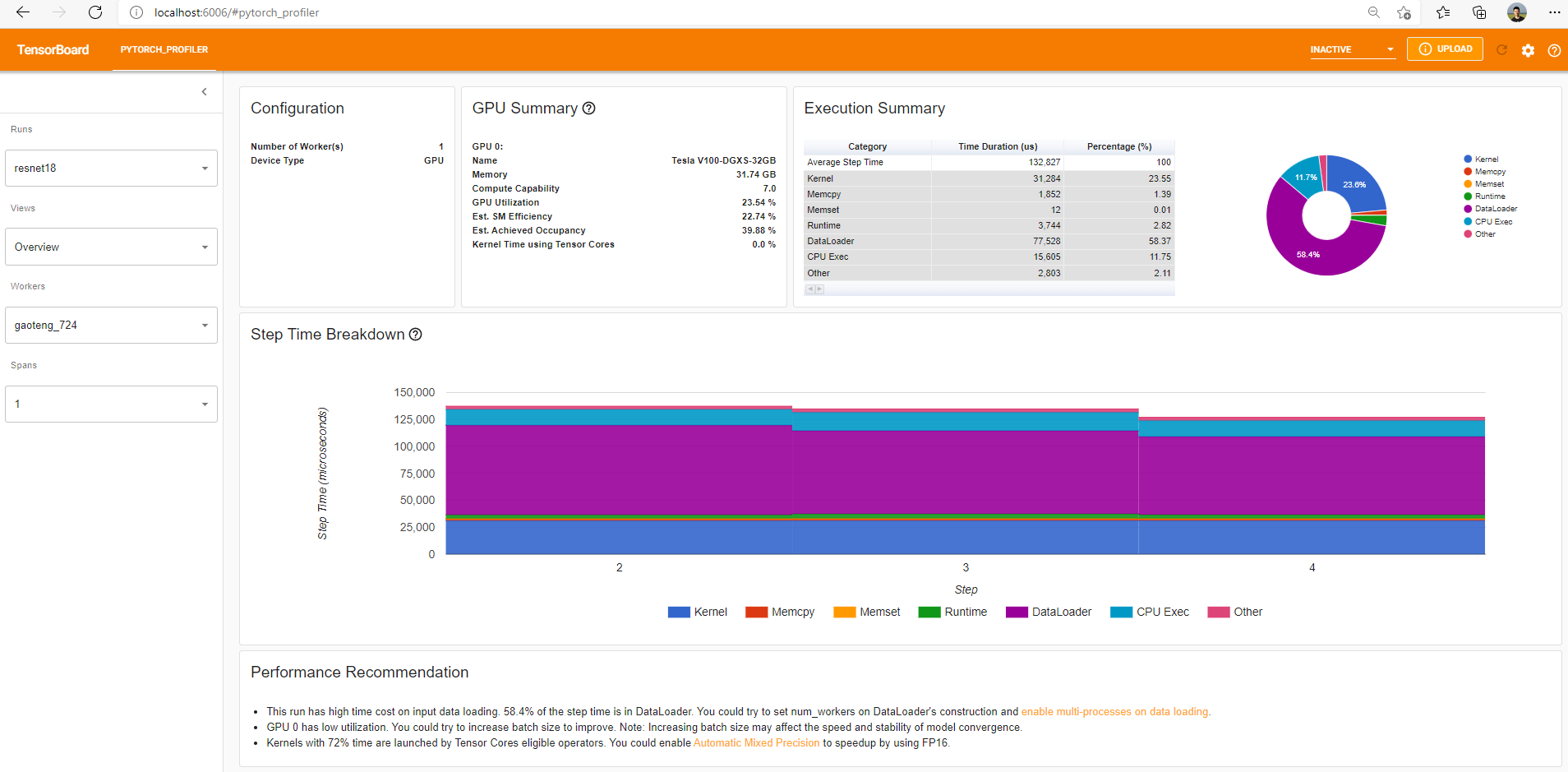
概覽顯示了模型效能的高層摘要。
“GPU Summary”面板顯示了 GPU 配置、GPU 使用率和 Tensor Cores 使用率。在此示例中,GPU 利用率較低。這些指標的詳細資訊 在此處。
“Step Time Breakdown”(步驟時間細分)顯示了每個步驟花費的時間在不同執行類別上的分佈。在此示例中,您可以看到 DataLoader 開銷相當顯著。
底部的“Performance Recommendation”(效能建議)利用 profiling 資料自動突出顯示可能的瓶頸,併為您提供可行的最佳化建議。
您可以在左側的“Views”(檢視)下拉列表中更改檢視頁面。
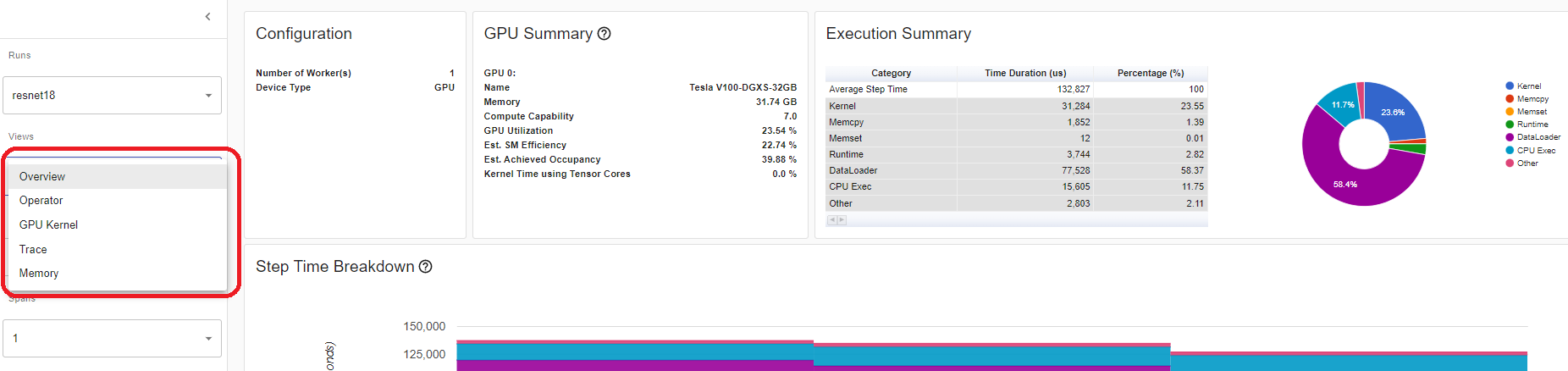
Operator view(運算元檢視)
運算元檢視顯示在主機或裝置上執行的每個 PyTorch 運算元的效能。
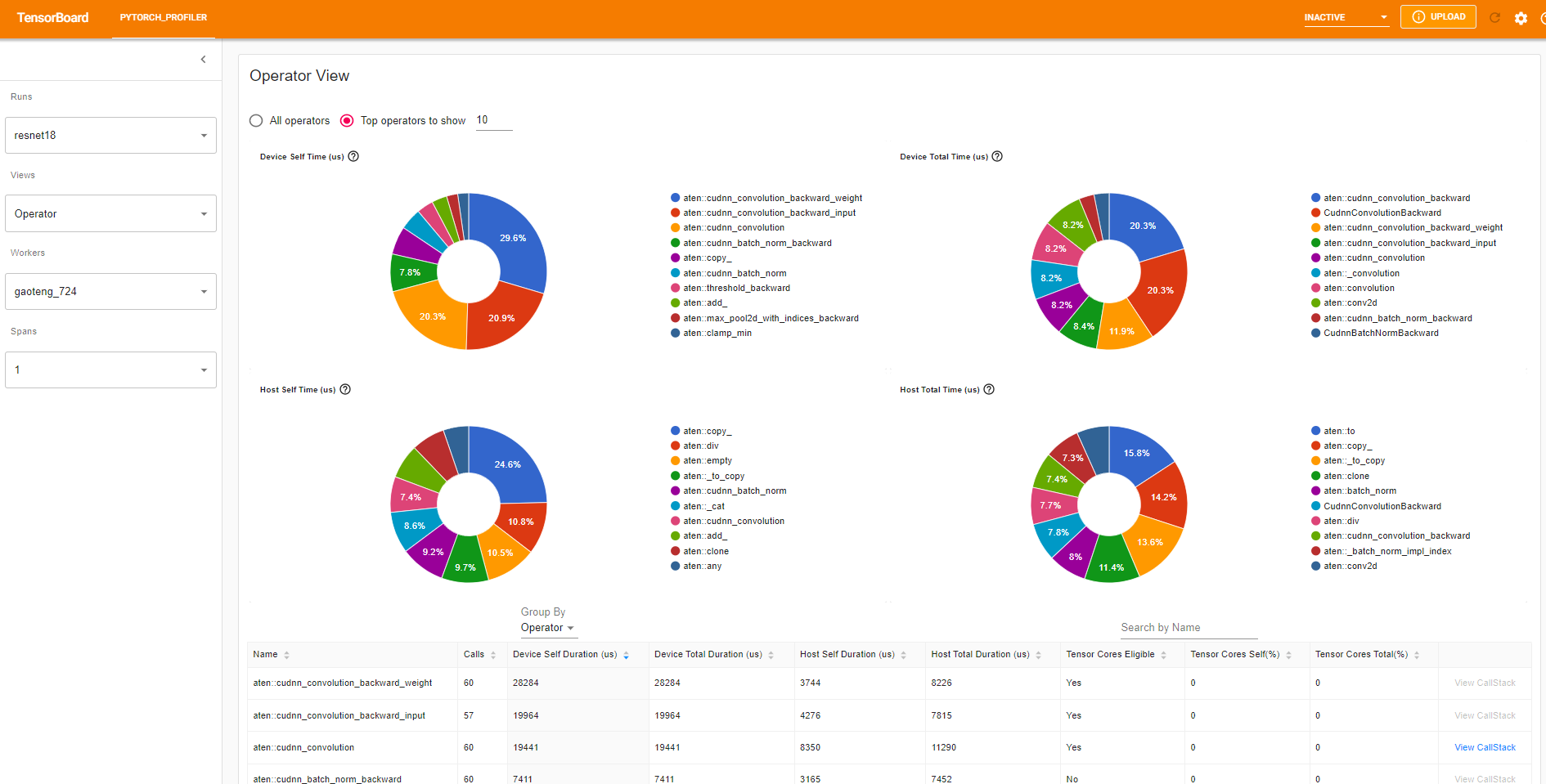
“Self” duration(自身持續時間)不包括其子運算元所花費的時間。“Total” duration(總持續時間)包括其子運算元所花費的時間。
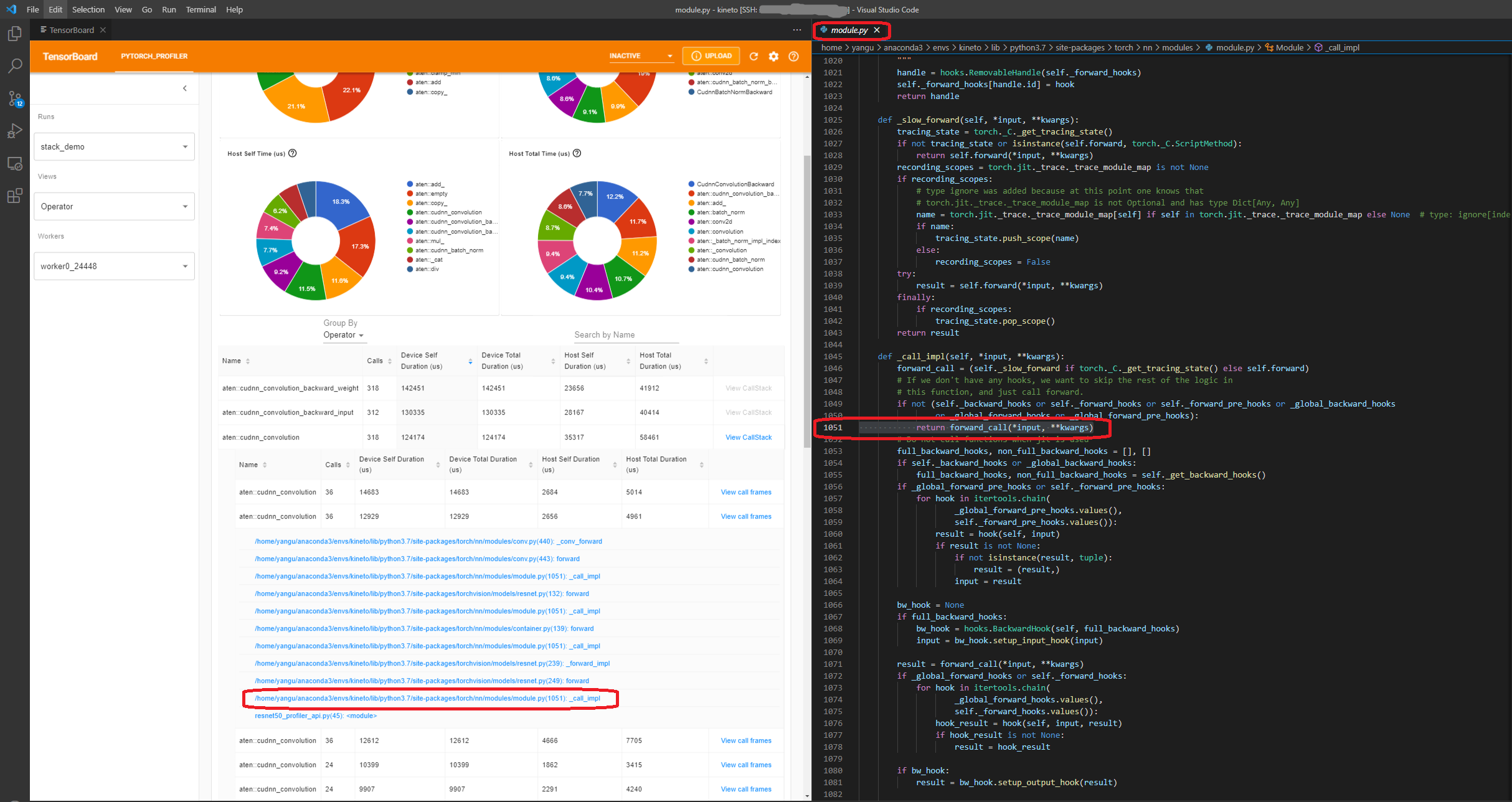
View call stack(檢視呼叫堆疊)
點選運算元的 View Callstack,將顯示名稱相同但呼叫堆疊不同的運算元。然後點選此子表中的 View Callstack,將顯示呼叫堆疊幀。
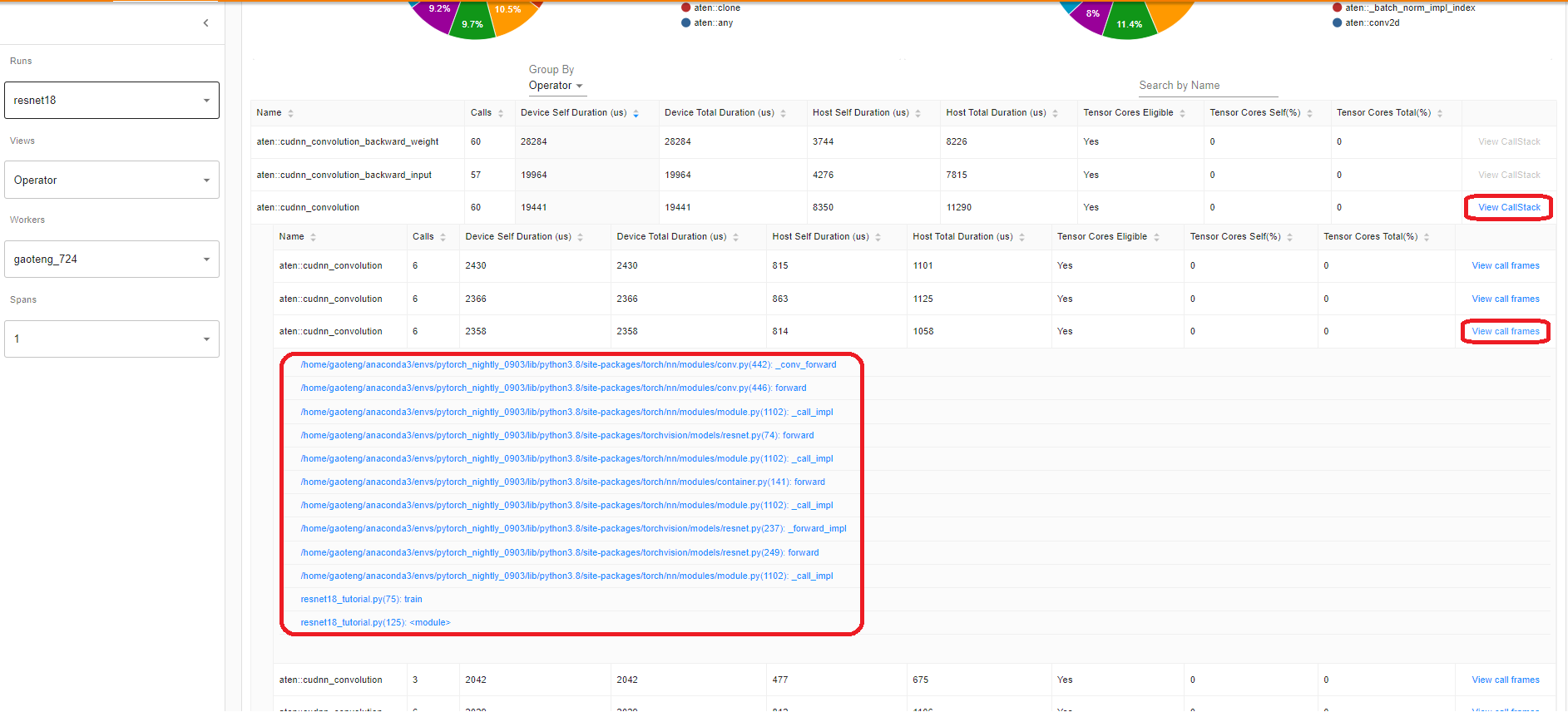
如果在 VS Code 中啟動 TensorBoard(啟動指南),單擊呼叫堆疊幀將導航到特定的程式碼行。
Kernel view(Kernel 檢視)
GPU kernel 檢視顯示所有 kernel 在 GPU 上花費的時間。
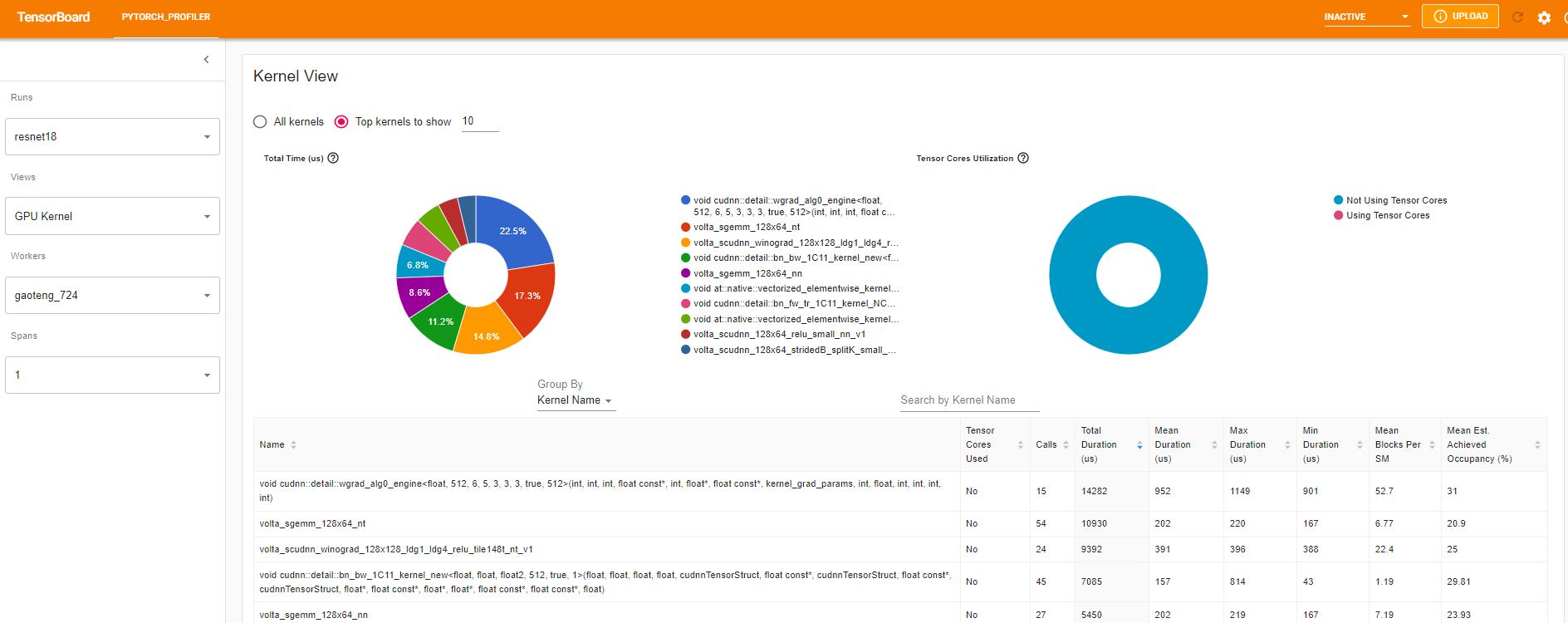
Tensor Cores Used(使用的 Tensor Cores):該 kernel 是否使用 Tensor Cores。
Mean Blocks per SM(每 SM 的平均 Blocks):Blocks per SM = 該 kernel 的 Blocks / 該 GPU 的 SM 數量。如果此數字小於 1,則表示 GPU 的多處理器未得到充分利用。“Mean Blocks per SM”是該 kernel 名稱所有執行的加權平均值,以每次執行的持續時間作為權重。
Mean Est. Achieved Occupancy(平均估計的達到佔用率):Est. Achieved Occupancy 在此列的工具提示中定義。對於大多數情況,如記憶體頻寬受限的 kernel,越高越好。“Mean Est. Achieved Occupancy”是該 kernel 名稱所有執行的加權平均值,以每次執行的持續時間作為權重。
Trace view(Trace 檢視)
Trace 檢視顯示了被 profiling 的運算元和 GPU kernel 的時間線。您可以選擇它來檢視如下詳細資訊。
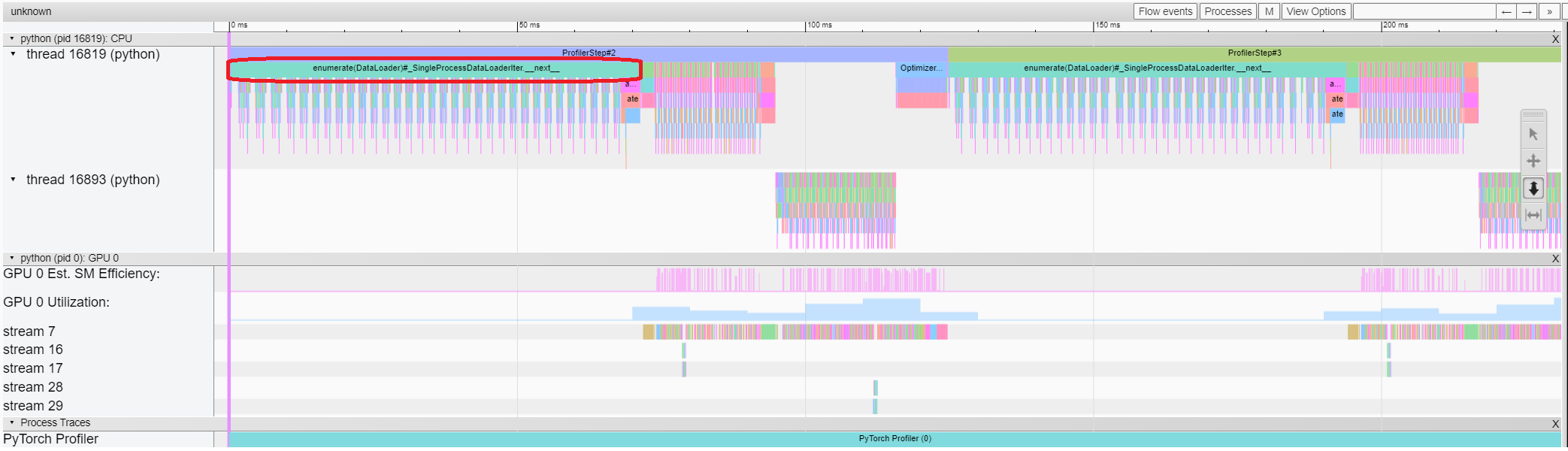
您可以使用右側工具欄來移動和縮放圖形。您還可以使用鍵盤在時間線內進行縮放和平移。'w' 和 's' 鍵以滑鼠為中心縮放,'a' 和 'd' 鍵將時間線向左或向右移動。您可以多次按下這些鍵,直到看到可讀的表示。
如果 backward 運算元的“Incoming Flow”(傳入流)欄位值為“forward correspond to backward”(前向對應後向),則可以單擊該文字以獲取其啟動的前向運算元。
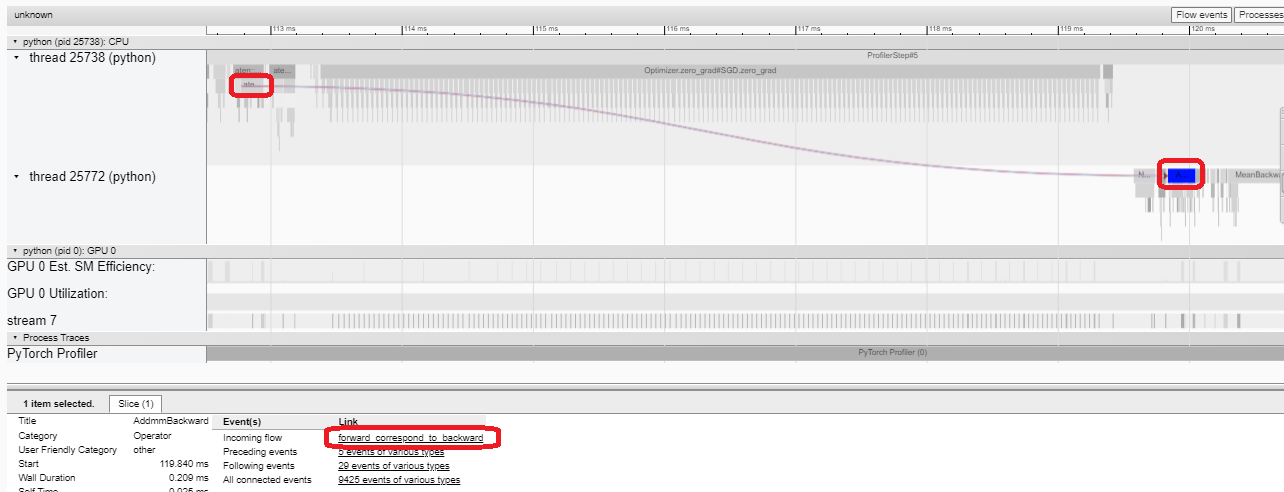
在本例中,我們可以看到帶有 enumerate(DataLoader) 字首的事件花費了大量時間。在這段時間的大部分時間裡,GPU 是空閒的。因為此函式在主機端載入資料和轉換資料,在此期間 GPU 資源被浪費了。
5. 在 profiler 的幫助下提升效能#
在“Overview”(概覽)頁面的底部,“Performance Recommendation”(效能建議)中的建議提示瓶頸是 DataLoader。PyTorch 的 DataLoader 預設使用單程序。使用者可以透過設定 num_workers 引數啟用多程序資料載入。更多細節在此。
在本例中,我們遵循“Performance Recommendation”(效能建議),將 num_workers 設定為如下所示,將 ./log/resnet18_4workers 這樣的不同名稱傳遞給 tensorboard_trace_handler,然後再次執行。
train_loader = torch.utils.data.DataLoader(train_set, batch_size=32, shuffle=True, num_workers=4)
然後,我們在左側的“Runs”(執行)下拉列表中選擇最近 profiling 的執行。
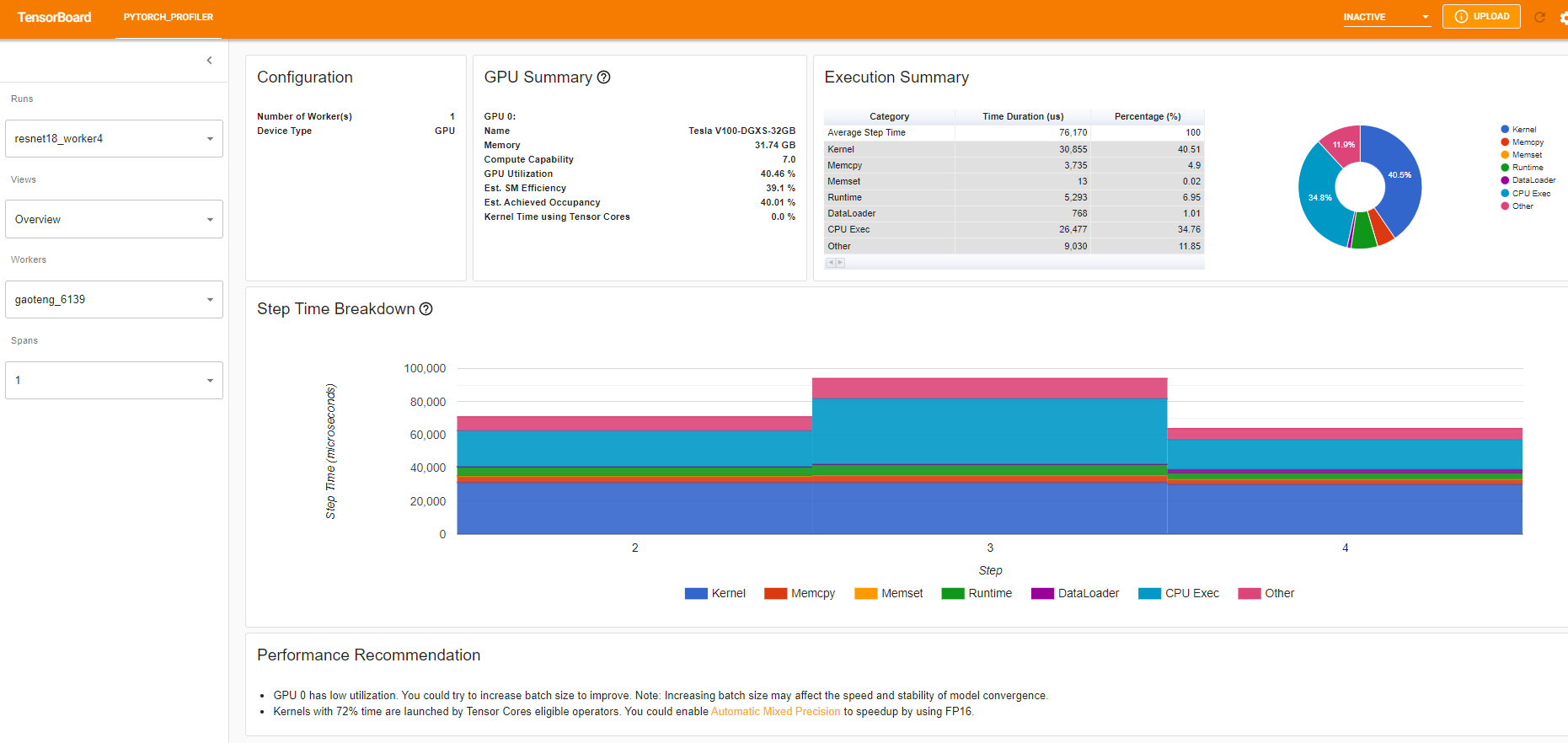
從上面的檢視中,我們可以發現步驟時間已減少到大約 76ms,而之前的執行時間為 132ms,DataLoader 時間的減少是主要原因。
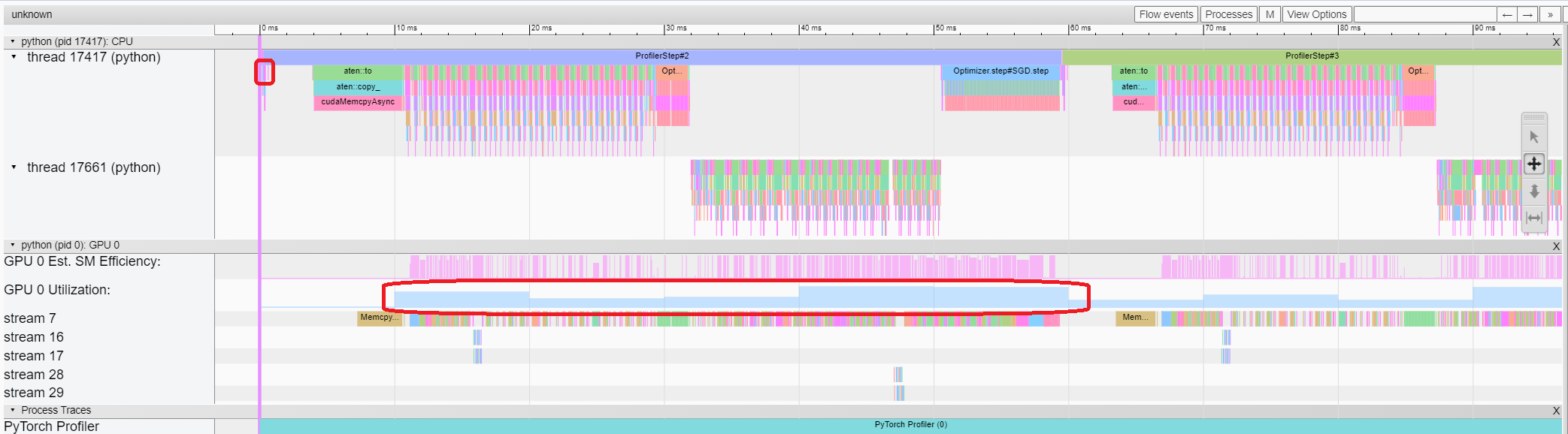
從上面的檢視中,我們可以看到 enumerate(DataLoader) 的執行時已減少,GPU 利用率已提高。
6. 使用其他高階功能分析效能#
Memory view(記憶體檢視)
要進行記憶體 profiling,必須在 torch.profiler.profile 的引數中將 profile_memory 設定為 True。
您可以在 Azure 上使用現有示例進行嘗試
pip install azure-storage-blob
tensorboard --logdir=https://torchtbprofiler.blob.core.windows.net/torchtbprofiler/demo/memory_demo_1_10
Profiler 在 profiling 期間記錄所有記憶體分配/釋放事件以及分配器的內部狀態。記憶體檢視由三個元件組成,如下所示。
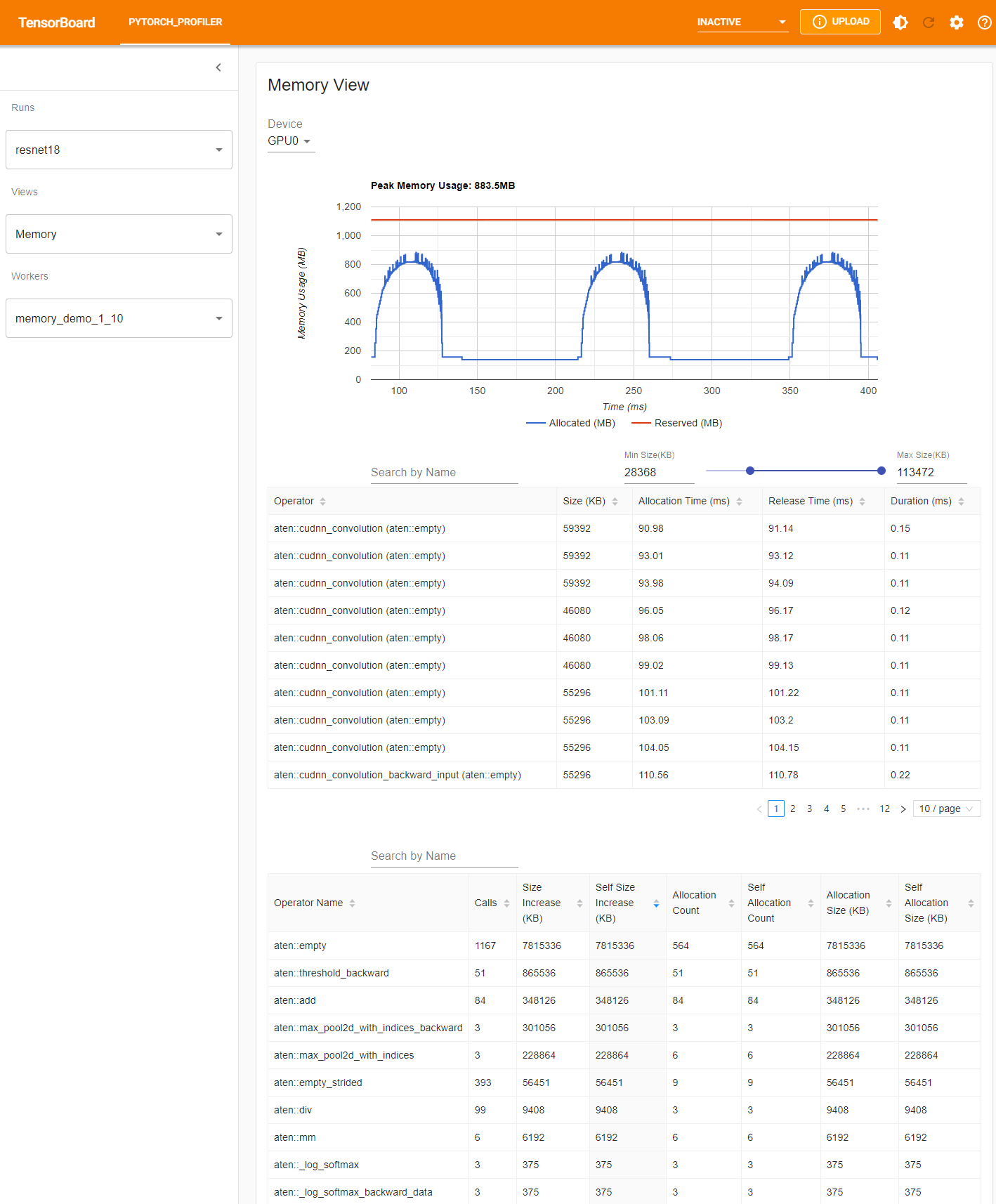
這些元件分別是記憶體曲線圖、記憶體事件表和記憶體統計表,從上到下依次排列。
可以在“Device”(裝置)選擇框中選擇記憶體型別。例如,“GPU0”表示下表僅顯示 GPU 0 上每個運算元的記憶體使用情況,不包括 CPU 或其他 GPU。
記憶體曲線顯示了記憶體消耗的趨勢。“Allocated”(已分配)曲線顯示了實際使用的總記憶體,例如張量。在 PyTorch 中,CUDA 分配器和其他一些分配器採用了快取機制。“Reserved”(已保留)曲線顯示了分配器已保留的總記憶體。您可以左鍵單擊並拖動圖表以選擇所需範圍內的事件。
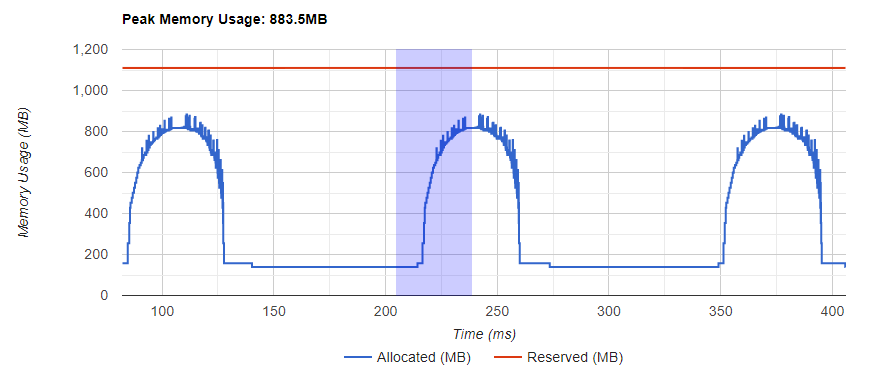
選擇後,這三個元件將針對受限時間範圍進行更新,以便您獲得更多關於它的資訊。透過重複此過程,您可以放大到非常精細粒度的細節。右鍵單擊圖表將圖表重置到初始狀態。
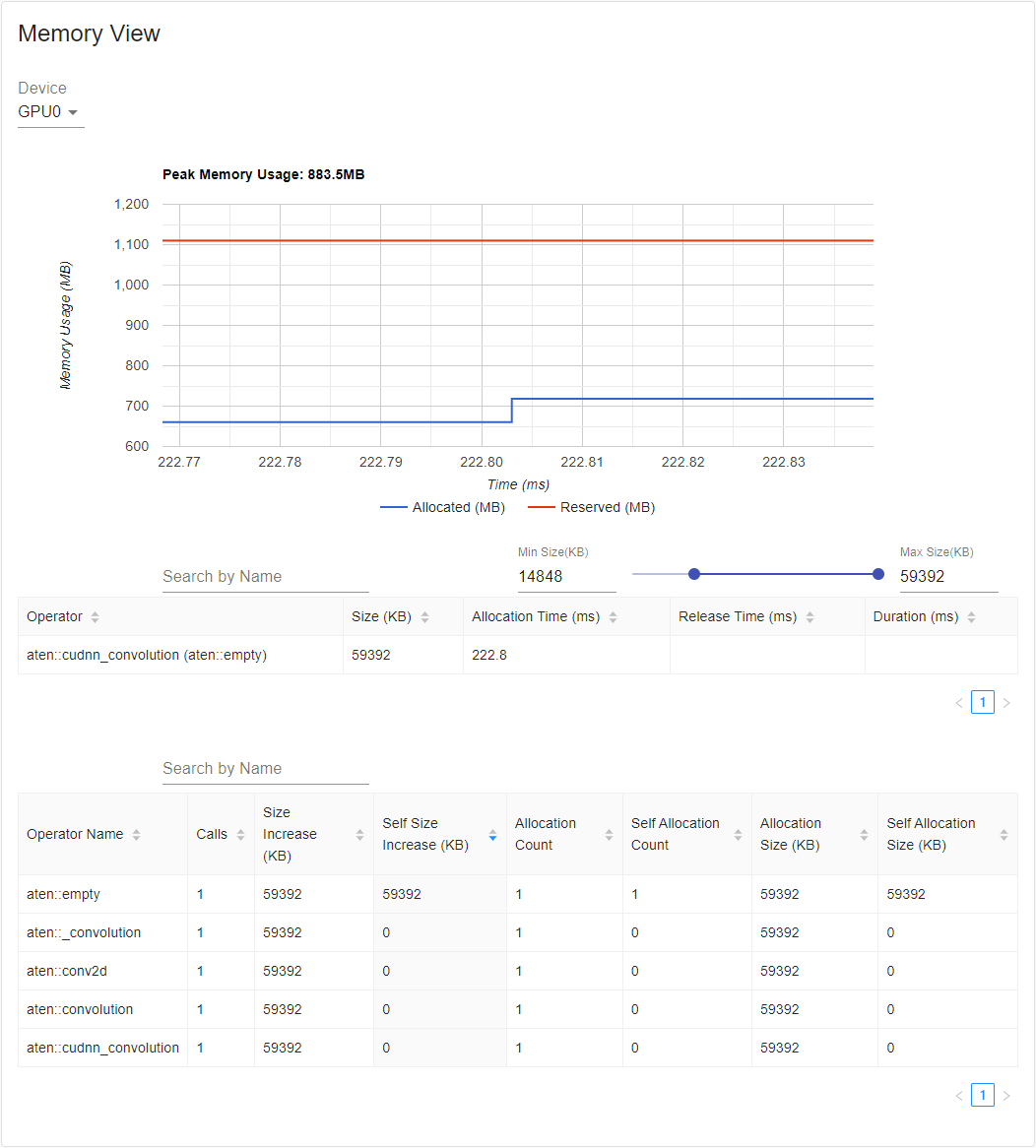
在記憶體事件表中,分配和釋放事件配對成一條記錄。“operator”(運算元)列顯示導致分配的直接 ATen 運算元。請注意,在 PyTorch 中,ATen 運算元通常使用 aten::empty 來分配記憶體。例如,aten::ones 實現為 aten::empty 後跟一個 aten::fill_。僅僅顯示 aten::empty 運算元名稱幫助不大。在這種特殊情況下,它將顯示為 aten::ones (aten::empty)。“Allocation Time”(分配時間)、“Release Time”(釋放時間)和“Duration”(持續時間)列的資料可能丟失,如果事件發生在所選時間範圍之外。
在記憶體統計表中,“Size Increase”(大小增加)列將所有分配大小相加並減去所有記憶體釋放大小,即此運算元後記憶體使用量的淨增加。“Self Size Increase”(自身大小增加)列類似於“Size Increase”,但它不計算子運算元的分配。關於 ATen 運算元的實現細節,某些運算元可能會呼叫其他運算元,因此記憶體分配可能發生在呼叫堆疊的任何級別。也就是說,“Self Size Increase”僅計算當前呼叫堆疊級別的記憶體使用量增加。最後,“Allocation Size”(分配大小)列將所有分配相加,而不考慮記憶體釋放。
Distributed view(分散式檢視)
該外掛現在支援在 profiling DDP(使用 NCCL/GLOO 作為後端)時進行分散式檢視。
您可以在 Azure 上使用現有示例進行嘗試
pip install azure-storage-blob
tensorboard --logdir=https://torchtbprofiler.blob.core.windows.net/torchtbprofiler/demo/distributed_bert
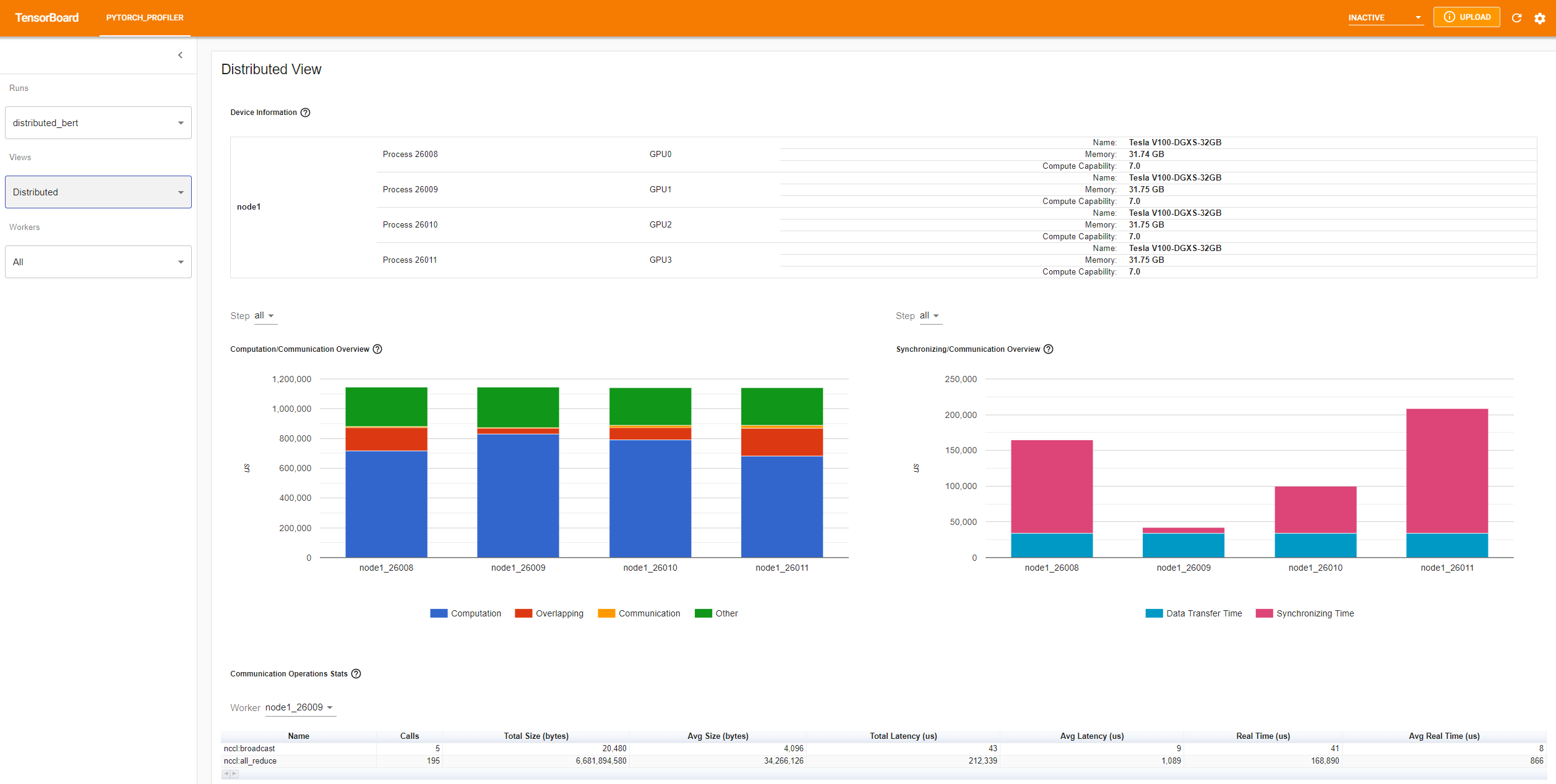
“Computation/Communication Overview”(計算/通訊概覽)顯示了計算/通訊的比例及其重疊程度。透過此檢視,使用者可以找出工作負載在 worker 之間的負載平衡問題。例如,如果一個 worker 的計算 + 重疊時間遠大於其他 worker,則可能存在負載平衡問題,或者該 worker 可能是落後者。
“Synchronizing/Communication Overview”(同步/通訊概覽)顯示了通訊效率。“Data Transfer Time”(資料傳輸時間)是實際資料交換的時間。“Synchronizing Time”(同步時間)是與其他 worker 等待和同步的時間。
如果一個 worker 的“Synchronizing Time”(同步時間)比其他 worker 短很多,則該 worker 可能是落後者,它可能比其他 worker 承擔了更多的計算工作負載。
“Communication Operations Stats”(通訊操作統計)彙總了每個 worker 中所有通訊操作的詳細統計資訊。
7. 額外實踐:在 AMD GPU 上進行 PyTorch profiling#
AMD ROCm 平臺是一個開源的 GPU 計算軟體棧,包括驅動程式、開發工具和 API。我們可以在 AMD GPU 上執行上述步驟。在本節中,我們將使用 Docker 在安裝 PyTorch 之前安裝 ROCm 基本開發映象。
為了舉例說明,讓我們建立一個名為 profiler_tutorial 的目錄,並將 **步驟 1** 中的程式碼儲存為 test_cifar10.py 在此目錄中。
mkdir ~/profiler_tutorial
cd profiler_tutorial
vi test_cifar10.py
截至本文撰寫之時,ROCm 平臺上的 PyTorch 的穩定版(2.1.1)Linux 版本為 ROCm 5.6。
從 Docker Hub 獲取安裝了正確使用者空間 ROCm 版本的基本 Docker 映象。
它是 rocm/dev-ubuntu-20.04:5.6。
啟動 ROCm 基本 Docker 容器
docker run -it --network=host --device=/dev/kfd --device=/dev/dri --group-add=video --ipc=host --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --shm-size 8G -v ~/profiler_tutorial:/profiler_tutorial rocm/dev-ubuntu-20.04:5.6
在容器內,安裝安裝 wheel 包所需的任何依賴項。
sudo apt update
sudo apt install libjpeg-dev python3-dev -y
pip3 install wheel setuptools
sudo apt install python-is-python3
安裝 wheels
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm5.6
安裝
torch_tb_profiler,然後執行 Python 檔案test_cifar10.py。
pip install torch_tb_profiler
cd /profiler_tutorial
python test_cifar10.py
現在,我們擁有在 TensorBoard 中檢視所需的所有資料
tensorboard --logdir=./log
選擇 **步驟 4** 中描述的不同檢視。例如,以下是 **Operator** 檢視。
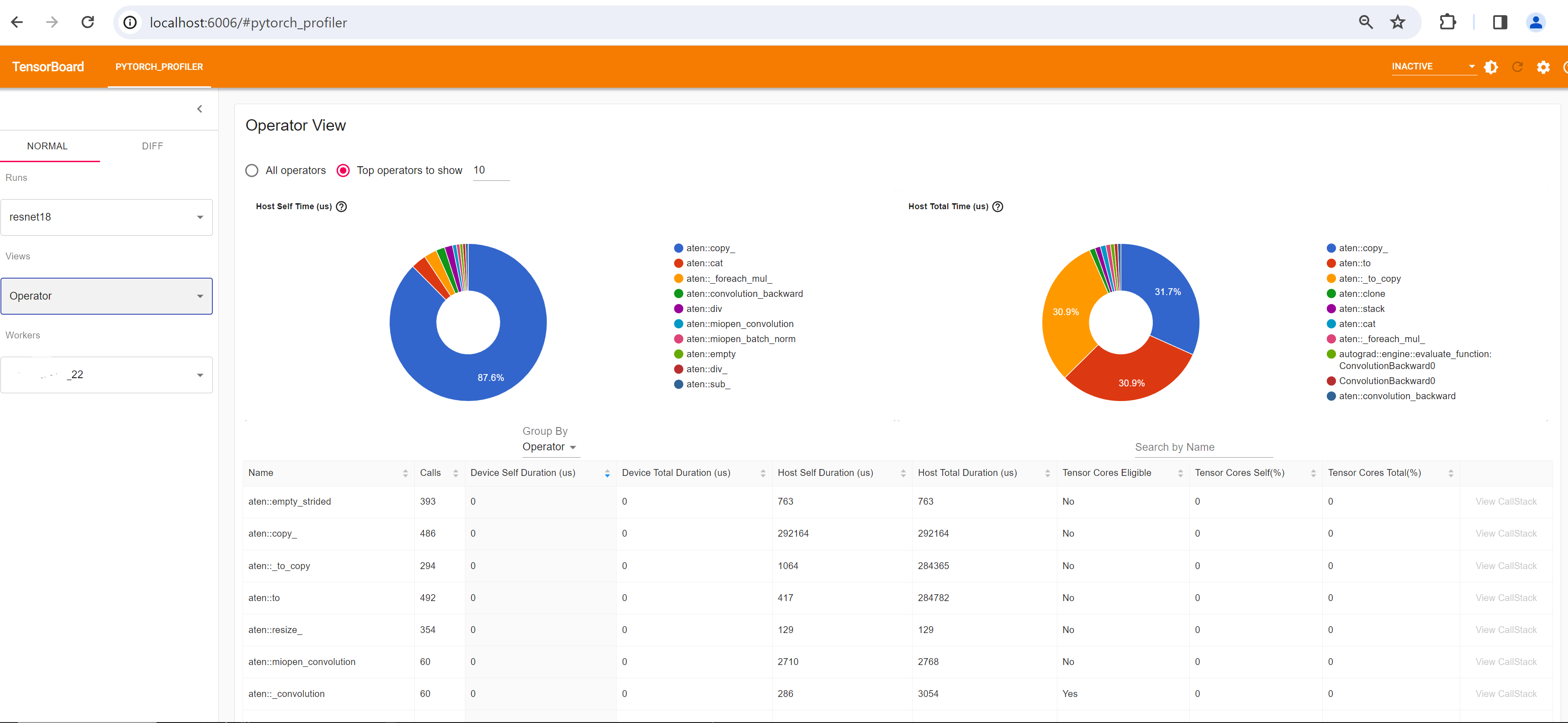
截至本文撰寫本文時,**Trace** 檢視不起作用,並且不顯示任何內容。您可以透過在 Chrome 瀏覽器中鍵入 chrome://tracing 來解決此問題。
將
~/profiler_tutorial/log/resnet18目錄下的trace.json檔案複製到 Windows。
如果檔案位於遠端位置,您可能需要使用 scp 複製該檔案。
在瀏覽器中的
chrome://tracing頁面上,單擊 **Load** 按鈕載入 trace JSON 檔案。
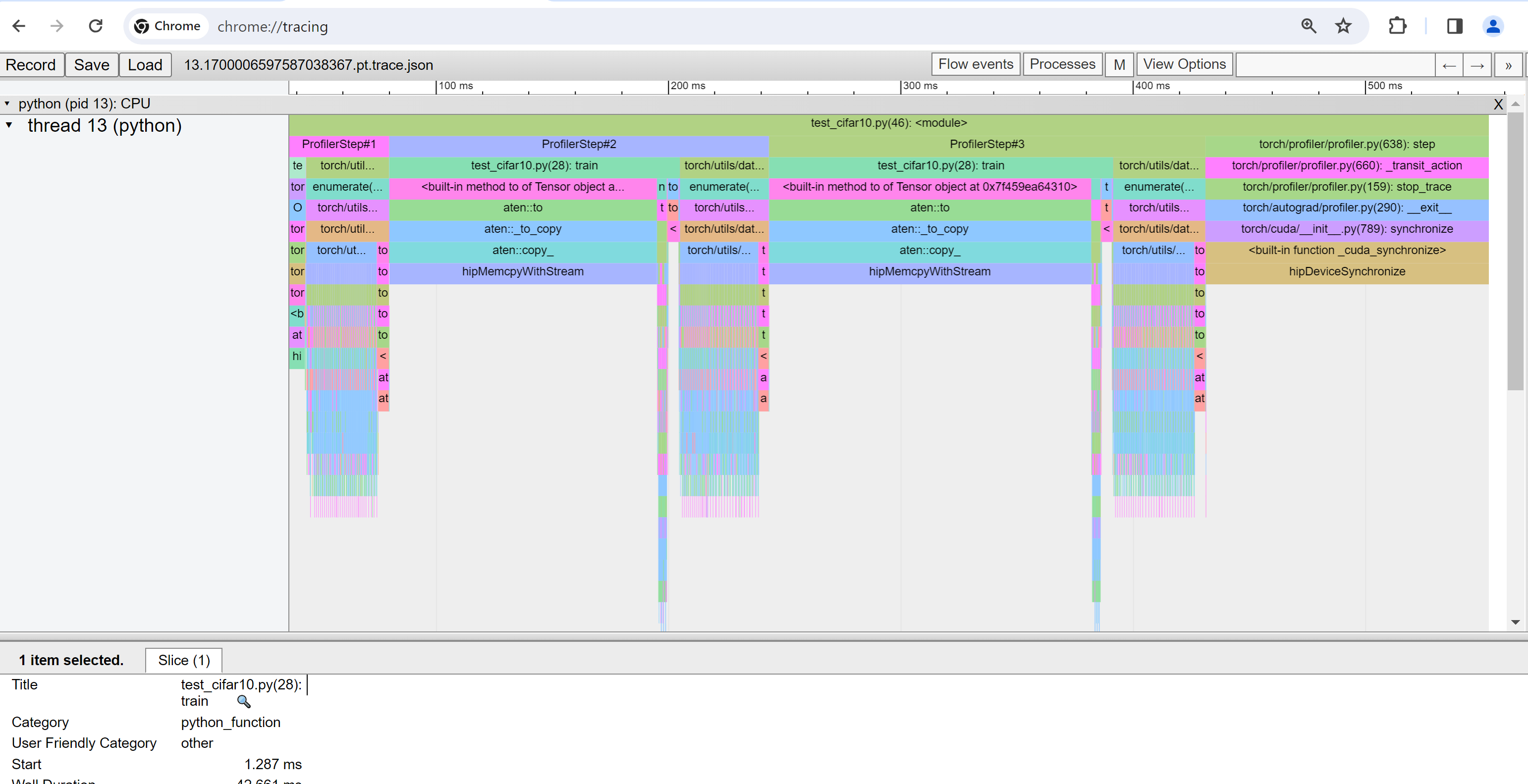
如前所述,您可以移動圖形並放大/縮小。您還可以使用鍵盤在時間線內進行縮放和平移。'w' 和 's' 鍵以滑鼠為中心縮放,'a' 和 'd' 鍵將時間線向左或向右移動。您可以多次按下這些鍵,直到看到可讀的表示。
瞭解更多#
請參閱以下文件以繼續您的學習,並隨時在此 處 提交 issues。
