使用非同步執行實現批次 RPC 處理#
建立日期:2020 年 7 月 28 日 | 最後更新:2025 年 6 月 23 日 | 最後驗證:未經驗證
作者:Shen Li
注意
 在 github 上檢視和編輯本教程。
在 github 上檢視和編輯本教程。
先決條件
本教程演示瞭如何使用 @rpc.functions.async_execution 裝飾器構建批次處理 RPC 應用程式,該裝飾器透過減少阻塞的 RPC 執行緒數量並整合被呼叫方上的 CUDA 操作來幫助加速訓練。
注意
本教程需要 PyTorch v1.6.0 或更高版本。
基礎#
之前的教程展示了使用 torch.distributed.rpc 構建分散式訓練應用程式的步驟,但並未詳細說明處理 RPC 請求時被呼叫方上發生的情況。從 PyTorch v1.5 開始,每個 RPC 請求都會在被呼叫方上阻塞一個執行緒,直到該函式返回為止來執行該請求中的函式。這適用於許多用例,但有一個注意事項。如果使用者函式阻塞在 I/O 上,例如巢狀 RPC 呼叫,或者阻塞在訊號上,例如等待另一個 RPC 請求解除阻塞,則被呼叫方上的 RPC 執行緒將不得不空閒等待直到 I/O 完成或訊號事件發生。結果是,RPC 被呼叫方可能使用比必要更多的執行緒。這個問題的原因在於 RPC 將使用者函式視為黑盒子,並且對函式中發生的事情瞭解甚少。為了允許使用者函式讓步並釋放 RPC 執行緒,需要向 RPC 系統提供更多提示。
自 v1.6.0 起,PyTorch 透過引入兩個新概念來解決這個問題:
一個 torch.futures.Future 型別,它封裝了一個非同步執行,並且還支援安裝回調函式。
一個 @rpc.functions.async_execution 裝飾器,它允許應用程式告訴被呼叫方目標函式將返回一個 Future,並且可以在執行過程中多次暫停和讓步。
有了這兩個工具,應用程式程式碼可以將使用者函式分解成多個更小的函式,將它們連結在一起作為 Future 物件的 istalation,並返回包含最終結果的 Future。在被呼叫方,當收到 Future 物件時,它會 istalation 後續的 RPC 響應準備和通訊作為 istalation,這些將在最終結果準備好時觸發。透過這種方式,被呼叫方不再需要阻塞一個執行緒並等待直到最終返回值準備好。有關簡單示例,請參閱 @rpc.functions.async_execution 的 API 文件。
除了減少被呼叫方上空閒執行緒的數量外,這些工具還有助於使批次 RPC 處理更容易和更快。本教程的以下兩個部分將演示如何使用 @rpc.functions.async_execution 裝飾器構建分散式批次更新引數伺服器和批次處理強化學習應用程式。
批次更新引數伺服器#
考慮一個具有一個引數伺服器 (PS) 和多個訓練器的同步引數伺服器訓練應用程式。在此應用程式中,PS 維護引數並等待所有訓練器報告梯度。在每個迭代中,它等待接收所有訓練器的梯度,然後一次性更新所有引數。下面的程式碼顯示了 PS 類的實現。update_and_fetch_model 方法使用 @rpc.functions.async_execution 進行裝飾,並將由訓練器呼叫。每次呼叫都會返回一個 Future 物件,該物件將被更新的模型填充。大多數訓練器發起的呼叫僅將梯度累積到 .grad 欄位,立即返回,並讓出 PS 上的 RPC 執行緒。最後一個到達的訓練器將觸發最佳化器步驟並消耗所有先前報告的梯度。然後它使用更新的模型設定 future_model,這反過來透過 Future 物件通知其他訓練器的所有先前請求,並將更新的模型傳送給所有訓練器。
import threading
import torchvision
import torch
import torch.distributed.rpc as rpc
from torch import optim
num_classes, batch_update_size = 30, 5
class BatchUpdateParameterServer(object):
def __init__(self, batch_update_size=batch_update_size):
self.model = torchvision.models.resnet50(num_classes=num_classes)
self.lock = threading.Lock()
self.future_model = torch.futures.Future()
self.batch_update_size = batch_update_size
self.curr_update_size = 0
self.optimizer = optim.SGD(self.model.parameters(), lr=0.001, momentum=0.9)
for p in self.model.parameters():
p.grad = torch.zeros_like(p)
def get_model(self):
return self.model
@staticmethod
@rpc.functions.async_execution
def update_and_fetch_model(ps_rref, grads):
# Using the RRef to retrieve the local PS instance
self = ps_rref.local_value()
with self.lock:
self.curr_update_size += 1
# accumulate gradients into .grad field
for p, g in zip(self.model.parameters(), grads):
p.grad += g
# Save the current future_model and return it to make sure the
# returned Future object holds the correct model even if another
# thread modifies future_model before this thread returns.
fut = self.future_model
if self.curr_update_size >= self.batch_update_size:
# update the model
for p in self.model.parameters():
p.grad /= self.batch_update_size
self.curr_update_size = 0
self.optimizer.step()
self.optimizer.zero_grad()
# by settiing the result on the Future object, all previous
# requests expecting this updated model will be notified and
# the their responses will be sent accordingly.
fut.set_result(self.model)
self.future_model = torch.futures.Future()
return fut
對於訓練器,它們都使用來自 PS 的相同引數集進行初始化。在每個迭代中,每個訓練器首先在本地執行前向和後向傳遞以生成梯度。然後,每個訓練器使用 RPC 將其梯度報告給 PS,並透過同一 RPC 請求的返回值獲取更新的引數。在訓練器的實現中,目標函式是否帶有 @rpc.functions.async_execution 裝飾器沒有區別。訓練器只需使用 rpc_sync 呼叫 update_and_fetch_model,它將阻塞訓練器直到更新的模型返回。
batch_size, image_w, image_h = 20, 64, 64
class Trainer(object):
def __init__(self, ps_rref):
self.ps_rref, self.loss_fn = ps_rref, torch.nn.MSELoss()
self.one_hot_indices = torch.LongTensor(batch_size) \
.random_(0, num_classes) \
.view(batch_size, 1)
def get_next_batch(self):
for _ in range(6):
inputs = torch.randn(batch_size, 3, image_w, image_h)
labels = torch.zeros(batch_size, num_classes) \
.scatter_(1, self.one_hot_indices, 1)
yield inputs.cuda(), labels.cuda()
def train(self):
name = rpc.get_worker_info().name
# get initial model parameters
m = self.ps_rref.rpc_sync().get_model().cuda()
# start training
for inputs, labels in self.get_next_batch():
self.loss_fn(m(inputs), labels).backward()
m = rpc.rpc_sync(
self.ps_rref.owner(),
BatchUpdateParameterServer.update_and_fetch_model,
args=(self.ps_rref, [p.grad for p in m.cpu().parameters()]),
).cuda()
我們在此教程中省略了啟動多個程序的程式碼,請參閱 examples 倉庫以獲取完整實現。請注意,無需 @rpc.functions.async_execution 裝飾器即可實現批次處理。但是,這需要阻塞更多 PS 上的 RPC 執行緒,或者使用另一輪 RPC 來獲取更新的模型,而後者將增加程式碼複雜性和通訊開銷。
本節使用一個簡單的引數伺服器訓練示例來展示如何使用 @rpc.functions.async_execution 裝飾器實現批次 RPC 應用程式。在下一節中,我們將使用批次處理重新實現先前 分散式 RPC 框架入門 教程中的強化學習示例,並展示其對訓練速度的影響。
批次處理 CartPole 求解器#
本節使用 OpenAI Gym 的 CartPole-v1 作為示例,展示批次處理 RPC 的效能影響。請注意,由於目標是演示 @rpc.functions.async_execution 的用法,而不是構建最佳 CartPole 求解器或解決大多數不同的 RL 問題,因此我們使用了非常簡單的策略和獎勵計算策略,並專注於多觀察者單智慧體批次 RPC 實現。我們使用了與先前教程類似的 Policy 模型,如下所示。與先前教程相比,區別在於其建構函式接受一個額外的 batch 引數,該引數控制 F.softmax 的 dim 引數,因為透過批次處理,forward 函式中的 x 引數包含來自多個觀察者的狀態,因此維度需要正確更改。其餘部分保持不變。
import argparse
import torch.nn as nn
import torch.nn.functional as F
parser = argparse.ArgumentParser(description='PyTorch RPC Batch RL example')
parser.add_argument('--gamma', type=float, default=1.0, metavar='G',
help='discount factor (default: 1.0)')
parser.add_argument('--seed', type=int, default=543, metavar='N',
help='random seed (default: 543)')
parser.add_argument('--num-episode', type=int, default=10, metavar='E',
help='number of episodes (default: 10)')
args = parser.parse_args()
torch.manual_seed(args.seed)
class Policy(nn.Module):
def __init__(self, batch=True):
super(Policy, self).__init__()
self.affine1 = nn.Linear(4, 128)
self.dropout = nn.Dropout(p=0.6)
self.affine2 = nn.Linear(128, 2)
self.dim = 2 if batch else 1
def forward(self, x):
x = self.affine1(x)
x = self.dropout(x)
x = F.relu(x)
action_scores = self.affine2(x)
return F.softmax(action_scores, dim=self.dim)
Observer 的建構函式也相應地進行了調整。它還接受一個 batch 引數,該引數控制它使用哪個 Agent 函式來選擇動作。在批次模式下,它在 Agent 上呼叫 select_action_batch 函式,該函式將在稍後展示,並且該函式將用 @rpc.functions.async_execution 進行裝飾。
import gym
import torch.distributed.rpc as rpc
class Observer:
def __init__(self, batch=True):
self.id = rpc.get_worker_info().id - 1
self.env = gym.make('CartPole-v1')
self.env.seed(args.seed)
self.select_action = Agent.select_action_batch if batch else Agent.select_action
與先前教程 分散式 RPC 框架入門 相比,觀察者的行為略有不同。當環境停止時,它不會退出,而是始終在每個 episode 中執行 n_steps 次迭代。當環境返回時,觀察者只需重置環境並重新開始。透過這種設計,智慧體將從每個觀察者那裡接收固定數量的狀態,因此可以將其打包成一個固定大小的張量。在每一步中,Observer 使用 RPC 將其狀態傳送給 Agent,並透過同一 RPC 請求的返回值獲取動作。在每個 episode 結束時,它將所有步驟的獎勵返回給 Agent。請注意,此 run_episode 函式將由 Agent 使用 RPC 呼叫。因此,此函式中的 rpc_sync 呼叫將是巢狀的 RPC 呼叫。我們也可以將此函式標記為 @rpc.functions.async_execution,以避免在 Observer 上阻塞一個執行緒。但是,由於瓶頸是 Agent 而不是 Observer,因此在 Observer 程序上阻塞一個執行緒是可以的。
import torch
class Observer:
...
def run_episode(self, agent_rref, n_steps):
state, ep_reward = self.env.reset(), NUM_STEPS
rewards = torch.zeros(n_steps)
start_step = 0
for step in range(n_steps):
state = torch.from_numpy(state).float().unsqueeze(0)
# send the state to the agent to get an action
action = rpc.rpc_sync(
agent_rref.owner(),
self.select_action,
args=(agent_rref, self.id, state)
)
# apply the action to the environment, and get the reward
state, reward, done, _ = self.env.step(action)
rewards[step] = reward
if done or step + 1 >= n_steps:
curr_rewards = rewards[start_step:(step + 1)]
R = 0
for i in range(curr_rewards.numel() -1, -1, -1):
R = curr_rewards[i] + args.gamma * R
curr_rewards[i] = R
state = self.env.reset()
if start_step == 0:
ep_reward = min(ep_reward, step - start_step + 1)
start_step = step + 1
return [rewards, ep_reward]
Agent 的建構函式還接受一個 batch 引數,該引數控制動作機率的批處理方式。在批次模式下,saved_log_probs 包含一個張量列表,其中每個張量包含一個步驟中所有觀察者的動作機率。沒有批次處理時,saved_log_probs 是一個字典,其中鍵是觀察者 ID,值是該觀察者動作機率的列表。
import threading
from torch.distributed.rpc import RRef
class Agent:
def __init__(self, world_size, batch=True):
self.ob_rrefs = []
self.agent_rref = RRef(self)
self.rewards = {}
self.policy = Policy(batch).cuda()
self.optimizer = optim.Adam(self.policy.parameters(), lr=1e-2)
self.running_reward = 0
for ob_rank in range(1, world_size):
ob_info = rpc.get_worker_info(OBSERVER_NAME.format(ob_rank))
self.ob_rrefs.append(rpc.remote(ob_info, Observer, args=(batch,)))
self.rewards[ob_info.id] = []
self.states = torch.zeros(len(self.ob_rrefs), 1, 4)
self.batch = batch
self.saved_log_probs = [] if batch else {k:[] for k in range(len(self.ob_rrefs))}
self.future_actions = torch.futures.Future()
self.lock = threading.Lock()
self.pending_states = len(self.ob_rrefs)
非批次處理的 select_acion 僅將狀態透過策略,儲存動作機率,並立即將動作返回給觀察者。
from torch.distributions import Categorical
class Agent:
...
@staticmethod
def select_action(agent_rref, ob_id, state):
self = agent_rref.local_value()
probs = self.policy(state.cuda())
m = Categorical(probs)
action = m.sample()
self.saved_log_probs[ob_id].append(m.log_prob(action))
return action.item()
透過批次處理,狀態儲存在二維張量 self.states 中,使用觀察者 ID 作為行 ID。然後,它透過 istalation 一個回撥函式來連結一個 Future 到批次生成的 self.future_actions Future 物件,該物件將被該觀察者 ID 索引的特定行填充。最後一個到達的觀察者一次性地將所有批次狀態透過策略,並相應地設定 self.future_actions。當發生這種情況時,istalation 在 self.future_actions 上的所有回撥函式將被觸發,並且它們的返回值將用於填充連結的 Future 物件,這反過來會通知 Agent 準備和通訊來自其他觀察者的所有先前 RPC 請求的響應。
class Agent:
...
@staticmethod
@rpc.functions.async_execution
def select_action_batch(agent_rref, ob_id, state):
self = agent_rref.local_value()
self.states[ob_id].copy_(state)
future_action = self.future_actions.then(
lambda future_actions: future_actions.wait()[ob_id].item()
)
with self.lock:
self.pending_states -= 1
if self.pending_states == 0:
self.pending_states = len(self.ob_rrefs)
probs = self.policy(self.states.cuda())
m = Categorical(probs)
actions = m.sample()
self.saved_log_probs.append(m.log_prob(actions).t()[0])
future_actions = self.future_actions
self.future_actions = torch.futures.Future()
future_actions.set_result(actions.cpu())
return future_action
現在讓我們定義不同的 RPC 函式如何被拼接在一起。Agent 控制每個 episode 的執行。它首先使用 rpc_async 在所有觀察者上啟動 episode,並阻塞返回的 future,這些 future 將被觀察者獎勵填充。請注意,下面的程式碼使用 RRef 輔助函式 ob_rref.rpc_async() 來啟動 run_episode 函式在 ob_rref RRef 的所有者上,並提供引數。然後,它將儲存的動作機率和返回的觀察者獎勵轉換為預期的 Gormat,並啟動訓練步驟。最後,它重置所有狀態並返回當前 episode 的獎勵。此函式是執行一個 episode 的入口點。
class Agent:
...
def run_episode(self, n_steps=0):
futs = []
for ob_rref in self.ob_rrefs:
# make async RPC to kick off an episode on all observers
futs.append(ob_rref.rpc_async().run_episode(self.agent_rref, n_steps))
# wait until all obervers have finished this episode
rets = torch.futures.wait_all(futs)
rewards = torch.stack([ret[0] for ret in rets]).cuda().t()
ep_rewards = sum([ret[1] for ret in rets]) / len(rets)
# stack saved probs into one tensor
if self.batch:
probs = torch.stack(self.saved_log_probs)
else:
probs = [torch.stack(self.saved_log_probs[i]) for i in range(len(rets))]
probs = torch.stack(probs)
policy_loss = -probs * rewards / len(rets)
policy_loss.sum().backward()
self.optimizer.step()
self.optimizer.zero_grad()
# reset variables
self.saved_log_probs = [] if self.batch else {k:[] for k in range(len(self.ob_rrefs))}
self.states = torch.zeros(len(self.ob_rrefs), 1, 4)
# calculate running rewards
self.running_reward = 0.5 * ep_rewards + 0.5 * self.running_reward
return ep_rewards, self.running_reward
其餘程式碼是與 RPC 教程類似的標準程序啟動和日誌記錄。在本教程中,所有觀察者都被動地等待來自智慧體的命令。請參閱 examples 倉庫以獲取完整實現。
def run_worker(rank, world_size, n_episode, batch, print_log=True):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '29500'
if rank == 0:
# rank0 is the agent
rpc.init_rpc(AGENT_NAME, rank=rank, world_size=world_size)
agent = Agent(world_size, batch)
for i_episode in range(n_episode):
last_reward, running_reward = agent.run_episode(n_steps=NUM_STEPS)
if print_log:
print('Episode {}\tLast reward: {:.2f}\tAverage reward: {:.2f}'.format(
i_episode, last_reward, running_reward))
else:
# other ranks are the observer
rpc.init_rpc(OBSERVER_NAME.format(rank), rank=rank, world_size=world_size)
# observers passively waiting for instructions from agents
rpc.shutdown()
def main():
for world_size in range(2, 12):
delays = []
for batch in [True, False]:
tik = time.time()
mp.spawn(
run_worker,
args=(world_size, args.num_episode, batch),
nprocs=world_size,
join=True
)
tok = time.time()
delays.append(tok - tik)
print(f"{world_size}, {delays[0]}, {delays[1]}")
if __name__ == '__main__':
main()
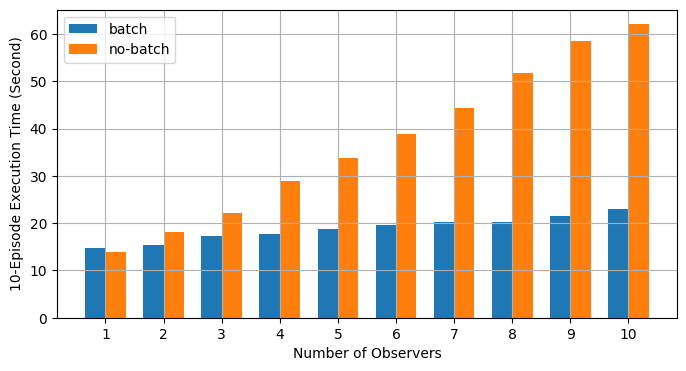
批次 RPC 有助於將動作推理整合到更少的 CUDA 操作中,從而降低了攤銷開銷。上述 main 函式使用不同數量的觀察者(從 1 到 10)在批次模式和非批次模式下執行相同的程式碼。下圖繪製了使用預設引數值時不同世界大小的執行時間。結果證實了我們的預期,即批次處理有助於加速訓練。