


使用 PyTorch 編寫分散式應用程式#
創建於: 2017 年 10 月 06 日 | 最後更新: 2025 年 09 月 05 日 | 最後驗證: 2024 年 11 月 05 日
作者: Séb Arnold
注意
 在 GitHub 上檢視和編輯此教程。
在 GitHub 上檢視和編輯此教程。
先決條件
在本簡短教程中,我們將介紹 PyTorch 的分散式包。我們將瞭解如何設定分散式環境,使用不同的通訊策略,以及深入瞭解該包的一些內部機制。
設定#
PyTorch 中包含的分散式包(即 torch.distributed)使研究人員和從業者能夠輕鬆地跨程序和機器叢集並行化計算。為此,它利用訊息傳遞語義,允許每個程序將資料傳輸到其他任何程序。與多程序 (torch.multiprocessing) 包不同,程序可以使用不同的通訊後端,並且不限於在同一臺機器上執行。
要開始,我們需要能夠同時執行多個程序。如果您有計算叢集的訪問許可權,請諮詢您的本地系統管理員或使用您喜歡的協調工具(例如 pdsh、clustershell 或 slurm)。本教程將使用單機,並透過以下模板生成多個程序。
"""run.py:"""
#!/usr/bin/env python
import os
import sys
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def run(rank, size):
""" Distributed function to be implemented later. """
pass
def init_process(rank, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank, world_size=size)
fn(rank, size)
if __name__ == "__main__":
world_size = 2
processes = []
if "google.colab" in sys.modules:
print("Running in Google Colab")
mp.get_context("spawn")
else:
mp.set_start_method("spawn")
for rank in range(world_size):
p = mp.Process(target=init_process, args=(rank, world_size, run))
p.start()
processes.append(p)
for p in processes:
p.join()
上面的指令碼會生成兩個程序,每個程序都會設定分散式環境,初始化程序組 (dist.init_process_group),最後執行給定的 run 函式。
讓我們看看 init_process 函式。它確保每個程序都能透過一個主節點進行協調,使用相同的 IP 地址和埠。請注意,我們使用了 gloo 後端,但還有其他後端可用。(參見 第 5.1 節)我們將在本教程的最後介紹 dist.init_process_group 中發生的“魔法”,但它本質上允許程序透過共享它們的位置來相互通訊。
點對點通訊#
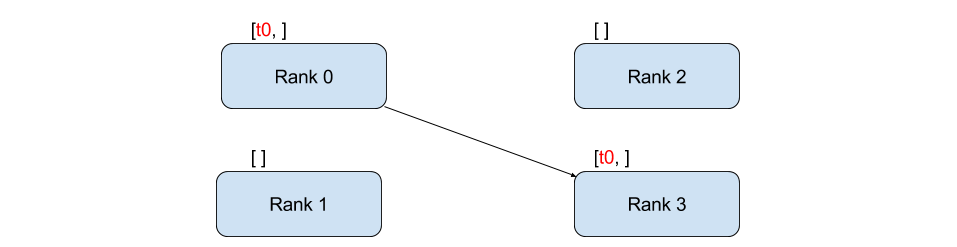
傳送和接收#
從一個程序到另一個程序的資料傳輸稱為點對點通訊。這些通訊透過 send 和 recv 函式或它們的即時對應函式 isend 和 irecv 來實現。
"""Blocking point-to-point communication."""
def run(rank, size):
tensor = torch.zeros(1)
if rank == 0:
tensor += 1
# Send the tensor to process 1
dist.send(tensor=tensor, dst=1)
else:
# Receive tensor from process 0
dist.recv(tensor=tensor, src=0)
print('Rank ', rank, ' has data ', tensor[0])
在上面的示例中,兩個程序都以零張量開始,然後程序 0 遞增張量並將其傳送到程序 1,以便它們都得到 1.0。請注意,程序 1 需要分配記憶體來儲存它將接收的資料。
另外請注意,send/recv 是阻塞的:兩個程序都會阻塞直到通訊完成。另一方面,即時函式是非阻塞的;指令碼繼續執行,並且這些方法在呼叫後返回一個 Work 物件,我們可以選擇對其呼叫 wait()。
"""Non-blocking point-to-point communication."""
def run(rank, size):
tensor = torch.zeros(1)
req = None
if rank == 0:
tensor += 1
# Send the tensor to process 1
req = dist.isend(tensor=tensor, dst=1)
print('Rank 0 started sending')
else:
# Receive tensor from process 0
req = dist.irecv(tensor=tensor, src=0)
print('Rank 1 started receiving')
req.wait()
print('Rank ', rank, ' has data ', tensor[0])
在使用即時函式時,我們必須小心如何使用傳送和接收的張量。由於我們不知道資料何時會傳輸到另一個程序,因此在 req.wait() 完成之前,我們不應修改傳送的張量,也不應訪問接收的張量。換句話說,
在
dist.isend()之後向tensor寫入將導致未定義行為。在
req.wait()執行之前,在dist.irecv()之後從tensor讀取將導致未定義行為。
但是,在 req.wait() 執行之後,我們可以保證通訊已發生,並且 tensor[0] 中儲存的值是 1.0。
點對點通訊在我們需要更精細地控制程序通訊時很有用。它們可用於實現複雜的演算法,例如 百度 DeepSpeech 或 Facebook 的大規模實驗中使用的演算法。(參見 第 4.1 節)
集體通訊#
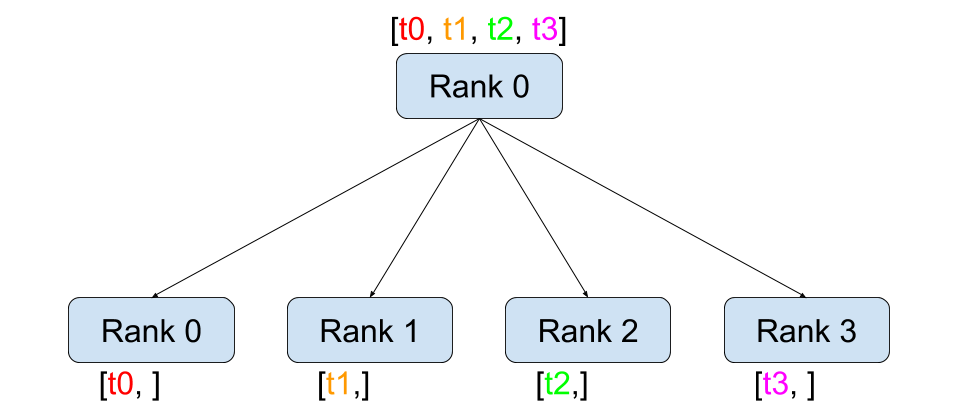
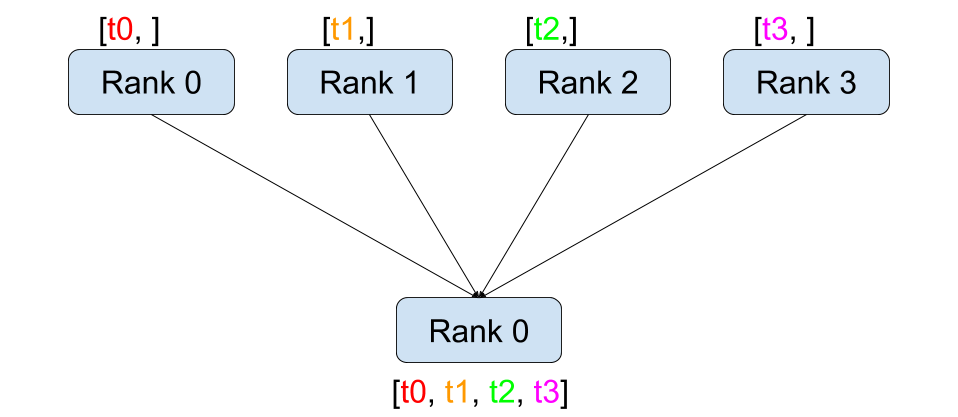
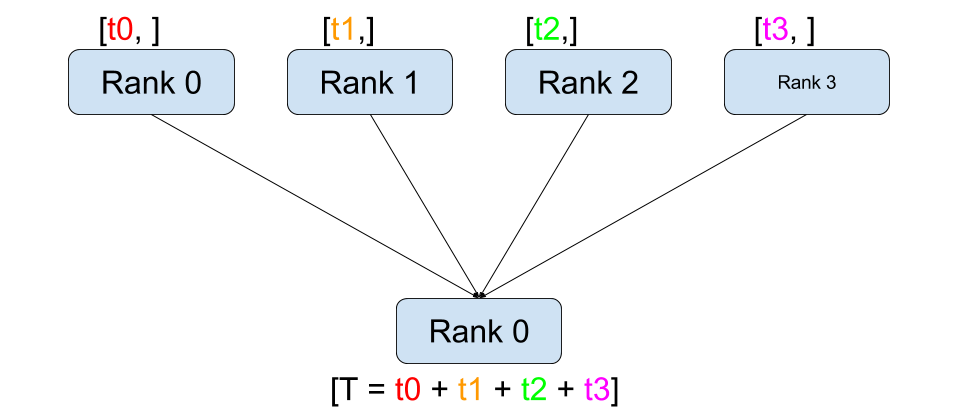
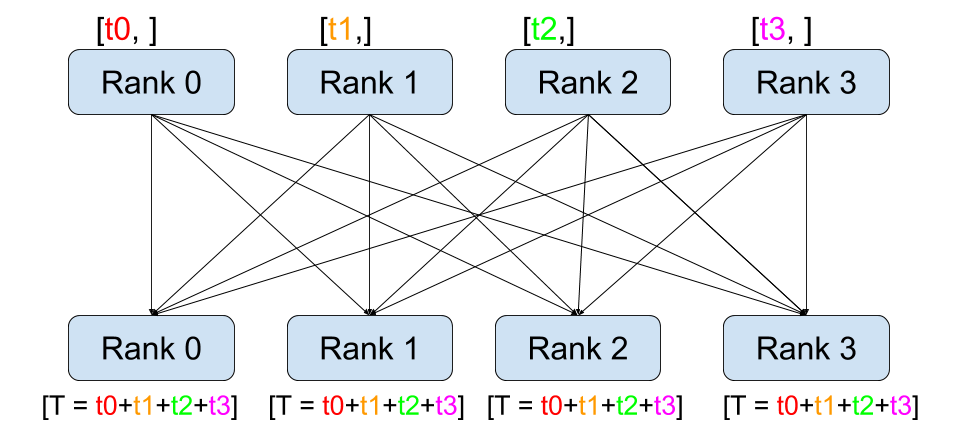
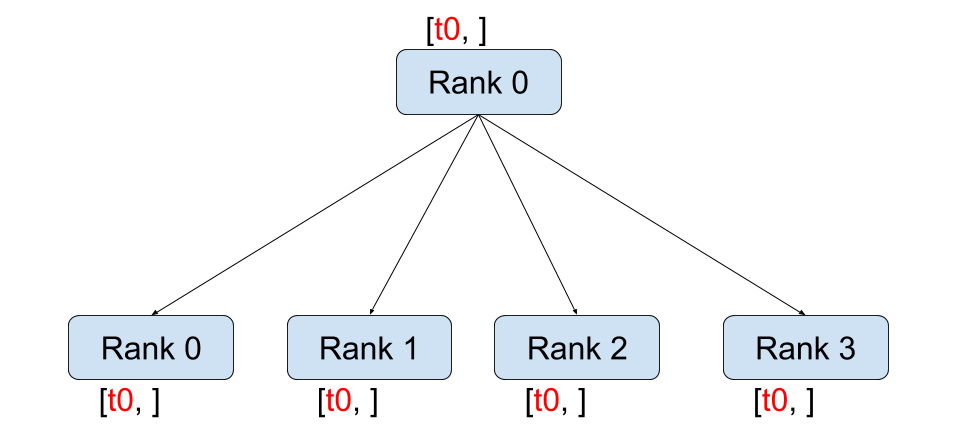
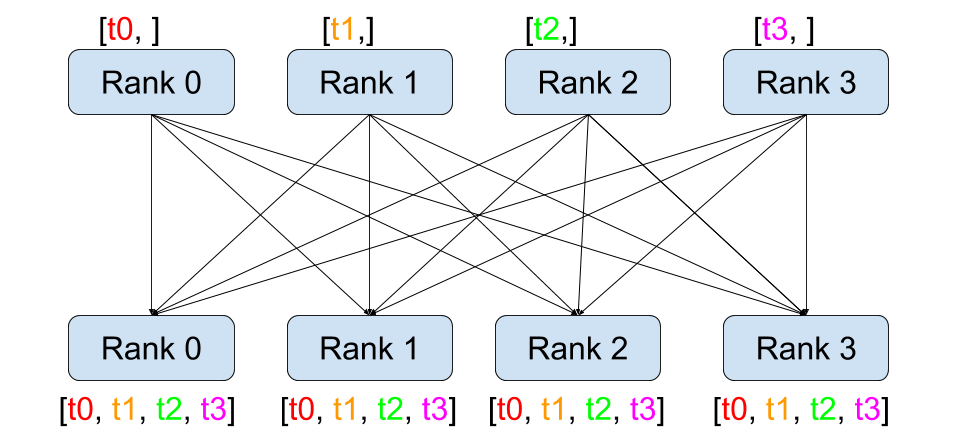
與點對點通訊相反,集體通訊允許在**組**中的所有程序之間進行通訊。組是我們所有程序的子集。要建立組,我們可以將一個排名列表傳遞給 dist.new_group(group)。預設情況下,集體通訊在所有程序上執行,也稱為**世界**。例如,為了獲得組中所有張量的總和,我們可以使用 dist.all_reduce(tensor, op, group) 集體。
""" All-Reduce example."""
def run(rank, size):
""" Simple collective communication. """
group = dist.new_group([0, 1])
tensor = torch.ones(1)
dist.all_reduce(tensor, op=dist.ReduceOp.SUM, group=group)
print('Rank ', rank, ' has data ', tensor[0])
由於我們想要組中所有張量的總和,因此我們將 dist.ReduceOp.SUM 用作歸約運算子。總的來說,任何可交換的數學運算都可以用作運算子。PyTorch 開箱即用地提供了許多此類運算子,它們都可以在元素級別上工作。
dist.ReduceOp.SUM,dist.ReduceOp.PRODUCT,dist.ReduceOp.MAX,dist.ReduceOp.MIN,dist.ReduceOp.BAND,dist.ReduceOp.BOR,dist.ReduceOp.BXOR,dist.ReduceOp.PREMUL_SUM.
支援的運算子的完整列表在此處:這裡。
除了 dist.all_reduce(tensor, op, group) 之外,PyTorch 目前還實現了許多其他集體通訊。以下是一些受支援的集體通訊。
dist.broadcast(tensor, src, group):將tensor從src複製到所有其他程序。dist.reduce(tensor, dst, op, group):將op應用於每個tensor,並將結果儲存在dst中。dist.all_reduce(tensor, op, group):與 reduce 相同,但結果儲存在所有程序中。dist.scatter(tensor, scatter_list, src, group):將 \(i^{\text{th}}\) 個張量scatter_list[i]複製到 \(i^{\text{th}}\) 個程序。dist.gather(tensor, gather_list, dst, group):將來自所有程序的tensor複製到dst。dist.all_gather(tensor_list, tensor, group):將所有程序的tensor複製到所有程序的tensor_list中。dist.barrier(group):阻塞 group 中的所有程序,直到每個程序都進入此函式。dist.all_to_all(output_tensor_list, input_tensor_list, group):將輸入張量列表分散到組中的所有程序,並在輸出列表中返回收集的張量列表。
支援的集體通訊的完整列表可以在 PyTorch Distributed 的最新文件中找到((連結))。
分散式訓練#
注意:您可以在 此 GitHub 儲存庫中找到本節的示例指令碼。
現在我們已經瞭解了分散式模組的工作原理,讓我們用它來編寫一些有用的東西。我們的目標是複製 DistributedDataParallel 的功能。當然,這將是一個教學示例,在實際應用中,您應該使用上面連結的官方、經過充分測試和最佳化的高版本。
很簡單,我們想實現一個分散式隨機梯度下降版本。我們的指令碼將允許所有程序計算其模型在資料批次上的梯度,然後對它們的梯度進行平均。為了確保在更改程序數量時獲得相似的收斂結果,我們首先需要劃分我們的資料集。(您也可以使用 torch.utils.data.random_split,而不是下面的程式碼片段。)
""" Dataset partitioning helper """
class Partition(object):
def __init__(self, data, index):
self.data = data
self.index = index
def __len__(self):
return len(self.index)
def __getitem__(self, index):
data_idx = self.index[index]
return self.data[data_idx]
class DataPartitioner(object):
def __init__(self, data, sizes=[0.7, 0.2, 0.1], seed=1234):
self.data = data
self.partitions = []
rng = Random() # from random import Random
rng.seed(seed)
data_len = len(data)
indexes = [x for x in range(0, data_len)]
rng.shuffle(indexes)
for frac in sizes:
part_len = int(frac * data_len)
self.partitions.append(indexes[0:part_len])
indexes = indexes[part_len:]
def use(self, partition):
return Partition(self.data, self.partitions[partition])
有了上面的程式碼片段,我們就可以使用以下幾行簡單地劃分任何資料集了。
""" Partitioning MNIST """
def partition_dataset():
dataset = datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
size = dist.get_world_size()
bsz = 128 // size
partition_sizes = [1.0 / size for _ in range(size)]
partition = DataPartitioner(dataset, partition_sizes)
partition = partition.use(dist.get_rank())
train_set = torch.utils.data.DataLoader(partition,
batch_size=bsz,
shuffle=True)
return train_set, bsz
假設我們有 2 個副本,那麼每個程序將擁有 60000 / 2 = 30000 個樣本的 train_set。我們還將副本數量除以批次大小,以保持 128 的總體批次大小。
我們現在可以編寫標準的向前-向後-最佳化訓練程式碼,並新增一個函式呼叫來平均我們模型的梯度。(以下內容在很大程度上受到了官方 PyTorch MNIST 示例的啟發。)
""" Distributed Synchronous SGD Example """
def run(rank, size):
torch.manual_seed(1234)
train_set, bsz = partition_dataset()
model = Net()
optimizer = optim.SGD(model.parameters(),
lr=0.01, momentum=0.5)
num_batches = ceil(len(train_set.dataset) / float(bsz))
for epoch in range(10):
epoch_loss = 0.0
for data, target in train_set:
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
epoch_loss += loss.item()
loss.backward()
average_gradients(model)
optimizer.step()
print('Rank ', dist.get_rank(), ', epoch ',
epoch, ': ', epoch_loss / num_batches)
現在還剩下實現 average_gradients(model) 函式,它只是接收一個模型並對其在整個世界中的梯度進行平均。
""" Gradient averaging. """
def average_gradients(model):
size = float(dist.get_world_size())
for param in model.parameters():
dist.all_reduce(param.grad.data, op=dist.ReduceOp.SUM)
param.grad.data /= size
搞定!我們成功實現了分散式同步 SGD,並且可以在大型計算機叢集上訓練任何模型。
注意:雖然最後一句話是技術上正確的,但要實現生產級別的同步 SGD 實現,還需要更多技巧。再次強調,請使用經過測試和最佳化的。
我們自己的環形 Allreduce#
作為額外的挑戰,假設我們想實現 DeepSpeech 的高效環形 allreduce。使用點對點集體通訊來實現這一點相當容易。
""" Implementation of a ring-reduce with addition. """
def allreduce(send, recv):
rank = dist.get_rank()
size = dist.get_world_size()
send_buff = send.clone()
recv_buff = send.clone()
accum = send.clone()
left = ((rank - 1) + size) % size
right = (rank + 1) % size
for i in range(size - 1):
if i % 2 == 0:
# Send send_buff
send_req = dist.isend(send_buff, right)
dist.recv(recv_buff, left)
accum[:] += recv_buff[:]
else:
# Send recv_buff
send_req = dist.isend(recv_buff, right)
dist.recv(send_buff, left)
accum[:] += send_buff[:]
send_req.wait()
recv[:] = accum[:]
在上面的指令碼中,allreduce(send, recv) 函式的簽名與 PyTorch 中的略有不同。它接受一個 recv 張量,並將所有 send 張量的總和儲存在該張量中。留給讀者作為練習,我們的版本與 DeepSpeech 中的版本仍有一個區別:它們的實現將梯度張量分成塊,以便最優地利用通訊頻寬。(提示:torch.chunk)
高階主題#
現在我們準備探索 torch.distributed 的一些更高階的功能。由於內容很多,本節分為兩個子節:
通訊後端:我們將瞭解如何使用 MPI 和 Gloo 進行 GPU-GPU 通訊。
初始化方法:我們將瞭解如何最好地設定
dist.init_process_group()中的初始協調階段。
通訊後端#
torch.distributed 最優雅的方面之一是它抽象和構建在不同後端之上的能力。如前所述,PyTorch 中實現了多個後端。這些後端可以使用加速器 API輕鬆選擇,該 API 提供了與不同加速器型別配合使用的介面。一些最流行的後端是 Gloo、NCCL 和 MPI。它們各自具有不同的規範和權衡,具體取決於所需的用例。支援函式的比較表可以在這裡找到。
Gloo 後端
到目前為止,我們已經廣泛使用了 Gloo 後端。它作為開發平臺非常方便,因為它包含在預編譯的 PyTorch 二進位制檔案中,並且可以在 Linux(自 0.2 起)和 macOS(自 1.3 起)上執行。它支援 CPU 上的所有點對點和集體操作,以及 GPU 上的所有集體操作。CUDA 張量的集體操作的實現不如 NCCL 後端提供的那麼最佳化。
您肯定已經注意到,如果我們把 model 放到 GPU 上,我們的分散式 SGD 示例將無法工作。為了使用多個 GPU,讓我們也進行以下修改:
使用加速器 API
device_type = torch.accelerator.current_accelerator()使用
torch.device(f"{device_type}:{rank}")model = Net()\(\rightarrow\)model = Net().to(device)使用
data, target = data.to(device), target.to(device)
透過這些修改,您的模型現在將在兩個 GPU 上進行訓練。如果您在 NVIDIA 硬體上執行,可以使用 watch nvidia-smi 來監控 GPU 利用率。
MPI 後端
訊息傳遞介面 (MPI) 是高效能計算領域的一種標準化工具。它允許進行點對點和集體通訊,並且是 torch.distributed API 的主要靈感來源。MPI 有多種實現(例如 Open-MPI、MVAPICH2、Intel MPI),每種實現都針對不同的目的進行了最佳化。使用 MPI 後端的優勢在於 MPI 在大型計算機叢集上的廣泛可用性和高水平最佳化。 一些 最近 實現還能夠利用 CUDA IPC 和 GPU Direct 技術,以避免透過 CPU 進行記憶體複製。
不幸的是,PyTorch 的二進位制檔案不能包含 MPI 實現,我們必須手動重新編譯它。幸運的是,這個過程相當簡單,因為在編譯時,PyTorch 會自行查詢可用的 MPI 實現。以下步驟透過從源安裝 PyTorch 來安裝 MPI 後端(from source)。
建立並激活您的 Anaconda 環境,按照指南安裝所有先決條件,但不要執行
python setup.py install。選擇並安裝您喜歡的 MPI 實現。請注意,啟用 CUDA 感知 MPI 可能需要一些額外的步驟。在本例中,我們將堅持使用 Open-MPI不帶GPU 支援:
conda install -c conda-forge openmpi現在,轉到您克隆的 PyTorch 倉庫並執行
python setup.py install。
為了測試我們新安裝的後端,需要進行一些修改。
將
if __name__ == '__main__':下的內容替換為init_process(0, 0, run, backend='mpi')。執行
mpirun -n 4 python myscript.py。
這些更改的原因是 MPI 需要在生成程序之前建立自己的環境。MPI 還會生成自己的程序並執行初始化方法中描述的握手,從而使 init_process_group 的 rank 和 size 引數變得多餘。這實際上非常強大,因為您可以將其他引數傳遞給 mpirun 以定製每個程序的計算資源。(例如每個程序的核心數、手動分配機器給特定排名,以及更多資訊)執行此操作後,您應該會獲得與使用其他通訊後端相同的熟悉輸出。
NCCL 後端
NCCL 後端提供了針對 CUDA 張量的集體操作的最佳化實現。如果您僅將 CUDA 張量用於集體操作,請考慮使用此後端以獲得最佳效能。NCCL 後端包含在支援 CUDA 的預構建二進位制檔案中。
XCCL 後端
XCCL 後端為 XPU 張量提供了集體操作的最佳化實現。如果您的工作負載僅將 XPU 張量用於集體操作,此後端可提供一流的效能。XCCL 後端包含在支援 XPU 的預構建二進位制檔案中。
初始化方法#
為了結束本教程,讓我們來審視一下我們之前呼叫的初始函式:dist.init_process_group(backend, init_method)。具體來說,我們將討論負責每個程序之間初步協調步驟的各種初始化方法。這些方法使您能夠定義如何完成此協調。
初始化方法的選擇取決於您的硬體設定,一種方法可能比其他方法更合適。除了以下各節,請參閱官方文件以獲取更多資訊。
環境變數
在本教程中,我們一直使用環境變數初始化方法。透過在所有機器上設定以下四個環境變數,所有程序都將能夠正確連線到主節點,獲取有關其他程序的資訊,並最終與它們進行握手。
MASTER_PORT:將在主機節點 0 排名程序的機器上使用的空閒埠。MASTER_ADDR:將主機節點 0 排名程序的機器的 IP 地址。WORLD_SIZE:總程序數,以便主節點知道需要等待多少工作程序。RANK:每個程序的排名,以便它們知道自己是主節點還是工作節點。
共享檔案系統
共享檔案系統要求所有程序能夠訪問共享檔案系統,並將透過共享檔案進行協調。這意味著每個程序都會開啟檔案,寫入其資訊,並等待直到所有程序都這樣做。之後,所有必需的資訊都將可供所有程序使用。為了避免競爭條件,檔案系統必須支援透過 fcntl 進行鎖定。
dist.init_process_group(
init_method='file:///mnt/nfs/sharedfile',
rank=args.rank,
world_size=4)
TCP
可以透過提供排名為 0 的程序的 IP 地址和一個可達的埠號來實現透過 TCP 進行初始化。在這裡,所有工作程序都將能夠連線到排名為 0 的程序,並交換有關如何相互訪問的資訊。
dist.init_process_group(
init_method='tcp://10.1.1.20:23456',
rank=args.rank,
world_size=4)
致謝
我要感謝 PyTorch 開發者在實現、文件和測試方面所做的出色工作。當代碼不清晰時,我總能依靠文件或測試來找到答案。特別是,我要感謝 Soumith Chintala、Adam Paszke 和 Natalia Gimelshein 為早期草稿提供了富有洞察力的評論和解答。
