


注意
轉到末尾 下載完整的示例程式碼。
透過將最佳化器步驟融合到反向傳播中來節省記憶體#
創建於:2023 年 10 月 02 日 | 最後更新於:2024 年 01 月 16 日 | 最後驗證於:2024 年 11 月 05 日
你好!本教程旨在展示一種透過減少梯度佔用的記憶體來降低訓練迴圈記憶體佔用的方法。假設你有一個模型,並且你對最佳化記憶體以避免 記憶體不足 (OOM) 錯誤或僅僅是為了從 GPU 中榨取更多效能感興趣。那麼,你可能走運了(如果梯度佔用了部分記憶體並且你不需要進行梯度累積)。我們將探討以下內容:
在訓練或微調迴圈中什麼會佔用記憶體,
如何捕獲和視覺化記憶體快照以確定瓶頸,
新的
Tensor.register_post_accumulate_grad_hook(hook)API,最後,在 10 行程式碼中如何將所有內容整合在一起以實現記憶體節省。
要執行本教程,您需要:
PyTorch 2.1.0 或更新版本及
torchvision1 個 CUDA GPU,如果您想在本地執行記憶體視覺化。否則,該技術在任何裝置上都會帶來類似的收益。
讓我們開始匯入所需的模組和模型。我們將使用 torchvision 中的 Vision Transformer 模型,但您可以隨意替換為您自己的模型。我們還將使用 torch.optim.Adam 作為我們的最佳化器,但同樣,您可以隨意替換為您自己的最佳化器。
import torch
from torchvision import models
from pickle import dump
model = models.vit_l_16(weights='DEFAULT').cuda()
optimizer = torch.optim.Adam(model.parameters())
Downloading: "https://download.pytorch.org/models/vit_l_16-852ce7e3.pth" to /var/lib/ci-user/.cache/torch/hub/checkpoints/vit_l_16-852ce7e3.pth
0%| | 0.00/1.13G [00:00<?, ?B/s]
3%|▎ | 29.5M/1.13G [00:00<00:03, 309MB/s]
6%|▌ | 70.9M/1.13G [00:00<00:02, 382MB/s]
10%|▉ | 114M/1.13G [00:00<00:02, 416MB/s]
14%|█▎ | 158M/1.13G [00:00<00:02, 432MB/s]
17%|█▋ | 201M/1.13G [00:00<00:02, 440MB/s]
21%|██ | 245M/1.13G [00:00<00:02, 446MB/s]
25%|██▍ | 289M/1.13G [00:00<00:02, 449MB/s]
29%|██▊ | 332M/1.13G [00:00<00:01, 451MB/s]
32%|███▏ | 375M/1.13G [00:00<00:01, 452MB/s]
36%|███▌ | 419M/1.13G [00:01<00:01, 453MB/s]
40%|███▉ | 462M/1.13G [00:01<00:01, 450MB/s]
44%|████▎ | 505M/1.13G [00:01<00:01, 451MB/s]
47%|████▋ | 549M/1.13G [00:01<00:01, 452MB/s]
51%|█████ | 592M/1.13G [00:01<00:01, 453MB/s]
55%|█████▍ | 636M/1.13G [00:01<00:01, 454MB/s]
58%|█████▊ | 679M/1.13G [00:01<00:01, 453MB/s]
62%|██████▏ | 722M/1.13G [00:01<00:01, 453MB/s]
66%|██████▌ | 766M/1.13G [00:01<00:00, 454MB/s]
70%|██████▉ | 809M/1.13G [00:01<00:00, 453MB/s]
73%|███████▎ | 852M/1.13G [00:02<00:00, 453MB/s]
77%|███████▋ | 896M/1.13G [00:02<00:00, 453MB/s]
81%|████████ | 939M/1.13G [00:02<00:00, 453MB/s]
85%|████████▍ | 982M/1.13G [00:02<00:00, 453MB/s]
88%|████████▊ | 1.00G/1.13G [00:02<00:00, 454MB/s]
92%|█████████▏| 1.04G/1.13G [00:02<00:00, 453MB/s]
96%|█████████▌| 1.09G/1.13G [00:02<00:00, 453MB/s]
100%|█████████▉| 1.13G/1.13G [00:02<00:00, 453MB/s]
100%|██████████| 1.13G/1.13G [00:02<00:00, 448MB/s]
現在,讓我們定義典型的訓練迴圈。您應該在訓練時使用真實影像,但出於本教程的目的,我們傳入的是虛假輸入,而不關心載入任何實際資料。
IMAGE_SIZE = 224
def train(model, optimizer):
# create our fake image input: tensor shape is batch_size, channels, height, width
fake_image = torch.rand(1, 3, IMAGE_SIZE, IMAGE_SIZE).cuda()
# call our forward and backward
loss = model.forward(fake_image)
loss.sum().backward()
# optimizer update
optimizer.step()
optimizer.zero_grad()
訓練期間的記憶體使用情況#
我們將要檢視一些記憶體快照,因此我們應該準備好正確地分析它們。通常,訓練記憶體包括:
模型引數(大小為 P)
為反向傳播儲存的啟用(大小為 A)
梯度,其大小與模型引數相同,因此大小為 G = P。
最佳化器狀態,它與引數的大小成正比。在這種情況下,Adam 的狀態需要模型引數的 2 倍,因此大小為 O = 2P。
中間張量,它們在計算過程中被分配。我們暫時不擔心它們,因為它們通常很小且短暫。
捕獲和視覺化記憶體快照#
讓我們來獲取記憶體快照!當您的程式碼執行時,請考慮 CUDA 記憶體時間線可能是什麼樣子。
# tell CUDA to start recording memory allocations
torch.cuda.memory._record_memory_history(enabled='all')
# train 3 steps
for _ in range(3):
train(model, optimizer)
# save a snapshot of the memory allocations
s = torch.cuda.memory._snapshot()
with open(f"snapshot.pickle", "wb") as f:
dump(s, f)
# tell CUDA to stop recording memory allocations now
torch.cuda.memory._record_memory_history(enabled=None)
現在,透過拖放 snapshot.pickle 檔案,在 https://pytorch.com.tw/memory_viz 開啟 CUDA 記憶體視覺化工具中的快照。記憶體時間線是否符合您的預期?
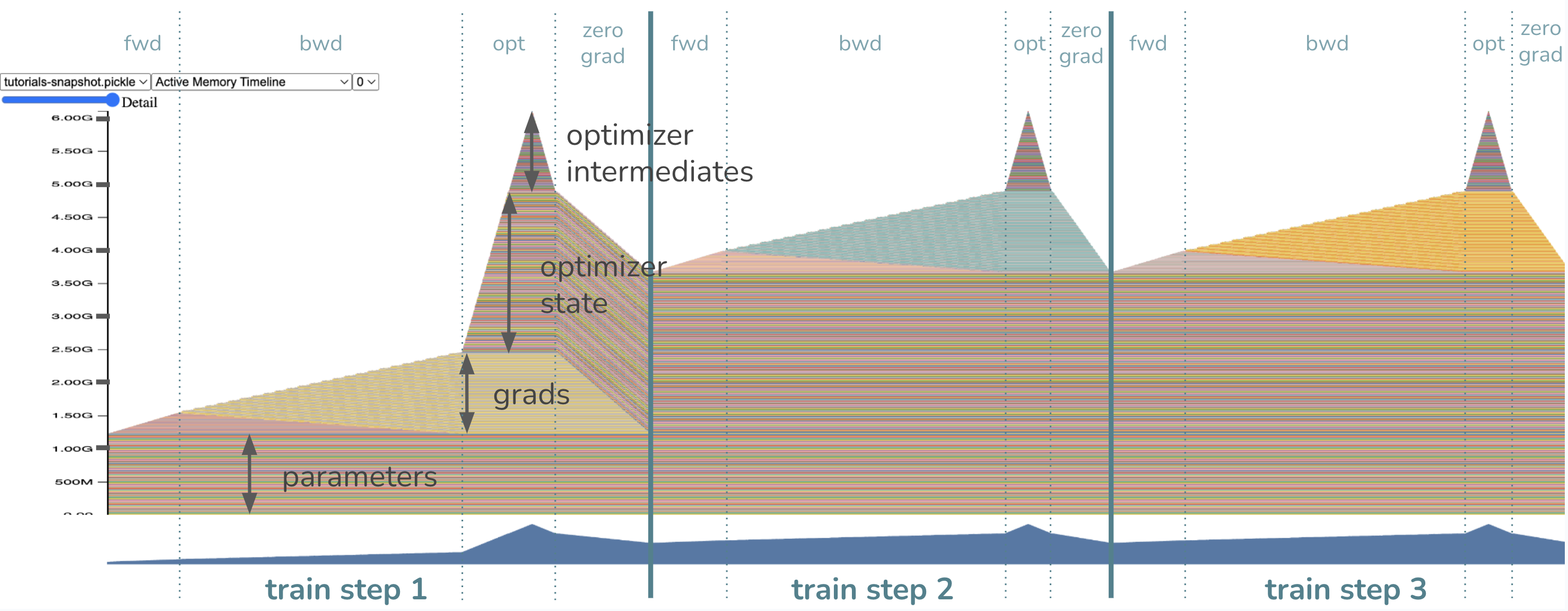
模型引數已在訓練步驟之前載入到記憶體中,因此我們一開始就能看到一部分記憶體專門用於權重。當我們開始前向傳播時,記憶體會逐漸分配給啟用,或者說我們儲存以便能夠在反向傳播中計算梯度的張量。一旦我們開始反向傳播,啟用會逐漸釋放,而梯度的記憶體則開始累積。
最後,當最佳化器啟動時,它的狀態將被惰性初始化,因此我們應該只在第一次訓練迴圈的最佳化器步驟中看到最佳化器狀態記憶體逐漸增加。在未來的迴圈中,最佳化器記憶體將保持不變並在原地更新。當呼叫 zero_grad 時,梯度記憶體會在每個訓練迴圈結束時相應地被釋放。
此訓練迴圈中的記憶體瓶頸在哪裡?換句話說,峰值記憶體是多少?
峰值記憶體使用量在最佳化器步驟期間!請注意,記憶體此時包括約 1.2GB 的引數、約 1.2GB 的梯度以及約 2.4GB=2*1.2GB 的最佳化器狀態,正如預期。最後的約 1.2GB 來自 Adam 最佳化器為中間值所需的記憶體,總計約 6GB 的峰值記憶體。嚴格來說,如果您將 Adam(model.parameters(), foreach=False) 設定為 foreach=False,則可以消除最後 1.2GB 的最佳化器中間值記憶體需求,但這會犧牲執行時間以換取記憶體。如果關閉 foreach 執行時最佳化對您來說足以節省記憶體,那很好,但如果您想知道本教程如何幫助您做得更好,請繼續閱讀!透過我們即將介紹的技術,我們將透過消除約 1.2GB 的梯度記憶體和最佳化器中間值記憶體的需求來降低峰值記憶體。那麼,您期望新的峰值記憶體是多少?答案將在下一個快照中揭曉。
免責宣告:這項技術並非適合所有人#
在我們過於興奮之前,我們必須考慮這項技術是否適用於您的用例。這不是萬能的!將最佳化器步驟融合到反向傳播中的技術僅針對減少梯度記憶體(並作為副作用,也減少最佳化器中間值記憶體)。因此,梯度佔用的記憶體越大,記憶體節省就越顯著。在我們上面的例子中,梯度佔用了 20% 的記憶體,這是一個相當大的比例!
對您而言可能並非如此,例如,如果您的權重已經很小(例如,由於應用了 LoRa),那麼梯度在訓練迴圈中佔用的空間並不多,收益也就不那麼令人興奮了。在這種情況下,您應該首先嚐試其他技術,例如啟用檢查點、分散式訓練、量化或減小批次大小。然後,當梯度再次成為瓶頸的一部分時,再回到本教程!
還在看?太棒了,讓我們在 Tensor 上介紹我們的新 register_post_accumulate_grad_hook(hook) API。
Tensor.register_post_accumulate_grad_hook(hook) API 和我們的技術#
我們的技術依賴於在 backward() 期間不儲存梯度。相反,一旦梯度被累積,我們將立即將最佳化器應用於相應的引數,並完全丟棄該梯度!這消除了在最佳化器步驟之前一直儲存大塊梯度的需求。
那麼,我們如何才能實現更積極地應用最佳化器的行為呢?在我們的 2.1 版本中,我們添加了一個新的 API torch.Tensor.register_post_accumulate_grad_hook(),它允許我們在 Tensor 的 .grad 欄位被累積後,向其新增一個鉤子。我們將把最佳化器步驟封裝到這個鉤子中。如何做?
在 10 行程式碼中如何將所有內容整合在一起#
還記得我們一開始的模型和最佳化器設定嗎?我將它們註釋掉,這樣我們就不必浪費資源重新執行程式碼。
model = models.vit_l_16(weights='DEFAULT').cuda()
optimizer = torch.optim.Adam(model.parameters())
# Instead of having just *one* optimizer, we will have a ``dict`` of optimizers
# for every parameter so we could reference them in our hook.
optimizer_dict = {p: torch.optim.Adam([p], foreach=False) for p in model.parameters()}
# Define our hook, which will call the optimizer ``step()`` and ``zero_grad()``
def optimizer_hook(parameter) -> None:
optimizer_dict[parameter].step()
optimizer_dict[parameter].zero_grad()
# Register the hook onto every parameter
for p in model.parameters():
p.register_post_accumulate_grad_hook(optimizer_hook)
# Now remember our previous ``train()`` function? Since the optimizer has been
# fused into the backward, we can remove the optimizer step and zero_grad calls.
def train(model):
# create our fake image input: tensor shape is batch_size, channels, height, width
fake_image = torch.rand(1, 3, IMAGE_SIZE, IMAGE_SIZE).cuda()
# call our forward and backward
loss = model.forward(fake_image)
loss.sum().backward()
# optimizer update --> no longer needed!
# optimizer.step()
# optimizer.zero_grad()
這在我們示例模型中大約需要 10 行的更改,這很不錯。但是,對於實際模型來說,將最佳化器替換為最佳化器字典可能會是一個相當大的改動,特別是對於那些使用 ``LRScheduler`` 或在訓練週期中操作最佳化器配置的人來說。讓這個 API 與這些更改協同工作將更加複雜,並且很可能需要將更多的配置移到全域性狀態中,但這並非不可能。也就是說,PyTorch 接下來的一個步驟是使該 API 更容易與 LRSchedulers 和您已經習慣的其他功能整合。
但是,讓我回到說服您這項技術值得一試。我們將諮詢我們的朋友——記憶體快照。
# delete optimizer memory from before to get a clean slate for the next
# memory snapshot
del optimizer
# tell CUDA to start recording memory allocations
torch.cuda.memory._record_memory_history(enabled='all')
# train 3 steps. note that we no longer pass the optimizer into train()
for _ in range(3):
train(model)
# save a snapshot of the memory allocations
s = torch.cuda.memory._snapshot()
with open(f"snapshot-opt-in-bwd.pickle", "wb") as f:
dump(s, f)
# tell CUDA to stop recording memory allocations now
torch.cuda.memory._record_memory_history(enabled=None)
是的,花點時間將您的快照拖入 CUDA 記憶體視覺化工具。

- 幾項主要觀察結果
沒有最佳化器步驟了!是的……我們已經將其融合到反向傳播中。
同樣,反向傳播的時間更長,並且有更多的中間隨機分配。這是預期的,因為最佳化器步驟需要中間值。
最重要的是!峰值記憶體降低了!現在約為 4GB(我希望這能與您之前的預期相符)。
請注意,與之前相比,不再有大量記憶體分配給梯度,節省了約 1.2GB 的記憶體。相反,我們透過儘可能提前移動最佳化器步驟,在計算完每個梯度後立即將其釋放。太棒了!順便說一句,另約 1.2GB 的記憶體節省來自於將最佳化器分解為每個引數的最佳化器,因此中間值的數量也相應地減少了。這個細節比梯度記憶體節省不那麼重要,因為您僅透過將 foreach=False 設定為 False 就可以節省最佳化器中間值記憶體,而無需此技術。
您可能正在正確地思考:如果我們節省了 2.4GB 的記憶體,為什麼峰值記憶體不是 6GB - 2.4GB = 3.6GB?嗯,峰值已經移動了!峰值現在位於反向傳播步驟的開始附近,此時我們仍然在記憶體中有啟用,而在之前,峰值是在最佳化器步驟期間,此時啟用已被釋放。因此,約 0.4GB 的差異(佔 4.0GB - 3.6GB)是由於啟用記憶體。然後,您可以想象這項技術可以與啟用檢查點結合使用以獲得更多記憶體收益。
結論#
在本教程中,我們透過新的 Tensor.register_post_accumulate_grad_hook() API 瞭解了將最佳化器融合到反向傳播步驟中以節省記憶體的技術,以及何時應用此技術(當梯度記憶體很重要時)。在此過程中,我們還學習了記憶體快照,它在記憶體最佳化方面非常有用。
指令碼總執行時間: (0 分鐘 8.892 秒)
